JPA使用总结
到了现阶段,JPA 的常用方法已经大部分掌握了,平时只需要使用 JPA 的 ORM 全自动管理,不需要使用一对多映射,配合 JdbcTemplate 就能很好的实现大部分业务开发
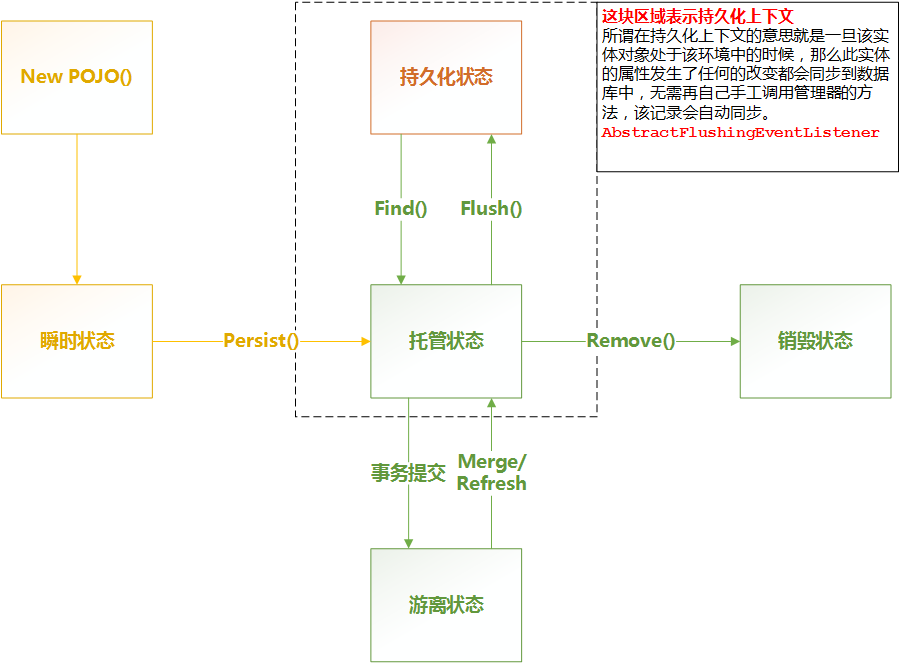
一、对象状态
| 临时状态 | 刚创建出来,与 EntityManager 没关系 |
|---|---|
| 托管状态 | JavaBean 与 Entitymanager 发生关系后被持久化,修改属性之后 JPA 会自动同步到数据库 |
| 持久化状态 | flush 之后就短暂进入持久化状态,提交事务之后变为游离态 |
| 游离态 | 事务提交之后,此时修改属性就没用了,如果 new 的对象,设置的 id 是数据库已存在的 ID,那也是游离态 |
二、ORM 全自动管理
强烈推荐使用的原因之一,表管理操作都可以在代码中实现,实体类即库表,配合 ide 的 jpa 插件很方便使用
不需要再直接使用数据库连接工具进行管理
- 可以进行索引管理和字段类型管理,包括字段注释,很方便
- 使用 hibernate 的**@SQLDelete和@Where**注解可以实现逻辑删除:JPQL 查询中会忽略已删除的数据;如果需要使用被删除的数据,编写 nativeQuery sql 即可
- 使用 innodb 引擎:在配置中加入 spring.jpa.properties.hibernate.dialect.storage_engine=innodb
1 | |
三、关键字查询
页面上搜索框需要对多个字段进行关键字模糊查询。其实搜索最好使用 ES。但我司业务比较轻,就没有使用 ES
- 在这里需要对工单号,参会专家,参会人员,客户单位,保修厂家,会议主题进行关键字搜索,是 or 搜索,还有其他的条件搜索,组合起来为一个多条件分页搜素
- 使用两个断言数组,一个存储 and 查询,一个存储关键字 or 查询即可。最后根据条件进行拼装。
1 | |
四、传参及查询结果的接收
以前使用 mybatis 的时会使用@Param 进行参数绑定, 在使用 JPA 的过程中每台注意,后来发现其实也是有类似注解的,这样会使代码更具有可读性,不必每次使用?1 进行参数的指定
一个实体有可能只需要其中的部分字段,这时可以使用 JPQL 的语法使用对应的 DTO 进行查询结果的接收
在 DTO 中定义好有参构造器即可,注意需要使用 DTO 的权限定类名进行接收
1 | |
五、基于注解的审计元数据
该部分部分来源为JPA 中文文档
很多时候需要自动填充的数据,如创建时间,更新时间,创建人,更新人
1 | |
AuditorAware
- 如果你使用 @CreatedBy 或 @LastModifiedBy,审计基础设施需要以某种方式知道当前的 principal。为此,我们提供了一个 AuditorAware
SPI 接口,你必须实现这个接口来告诉基础设施谁是与应用程序交互的当前用户或系统。泛型 T 定义了用 @CreatedBy 或 @LastModifiedBy 注解的属性必须是什么类型。 下面的例子显示了一个使用 Spring Security 的 Authentication 对象的接口实现
1 | |
ReactiveAuditorAware
当使用响应式基础设施时,你可能想利用上下文(Context)信息来提供 @CreatedBy 或 @LastModifiedBy 信息。我们提供了一个 ReactiveAuditorAware
SPI 接口,你必须实现这个接口来告诉基础设施谁是当前与应用程序交互的用户或系统。泛型 T 定义了用 @CreatedBy 或 @LastModifiedBy 注释的属性必须是什么类型。
下面的例子显示了一个接口的实现,它使用了 Spring Security 的 Authentication 对象。
Example 124. 基于 Spring Security 的 ReactiveAuditorAware 的实现
1 | |
该实现访问由 Spring Security 提供的 Authentication 对象,并查找你在 UserDetailsService 实现中创建的自定义 UserDetails 实例。我们在这里假设你是通过 UserDetails 实现来暴露 domain 用户的,但根据找到的 Authentication,你也可以从任何地方查到它。
还有一个方便的基类,AbstractAuditable,你可以扩展它以避免手动实现接口方法。这样做会增加你的 domain 类与 Spring Data 的耦合度,这可能是你想避免的事情。通常情况下,基于注解的定义审计元数据的方式更受欢迎,因为它的侵入性更小,也更灵活。
六、批处理
JPA 默认的 saveAllAndFlush 速度太慢,一般在性能要求不高的场景下使用;当有大量数据需要存储时,速度会特别慢,因此进行优化。我在平时工作中一般会使用 jdbcTemplate 进行管理
- 配置文件的变化
1 | |
- 具体使用
1 | |
- 经过测试之后,也确实证实了 jdbcTemplate 速度的优异性
- 测试结果为:
1 | |
- 测试程序如下
1 | |
七、杂想
- 总的来说个人还是更喜欢使用 JPA 的,在编写 JPQL 的时候如果又字段不对,IDEA 也会进行对应的标红提示,基本做到了类型安全。
- 在开发中,简单的 sql 使用 jpa 内置方法,声明符合规则的方法即可,较复杂的使用 JPQL 查询也可以解决很多问题。更复杂的可以使用 Specification 构建查询规则,或者使用 jdbcTemplate 完全手写 sql 也很不错
- 希望开发中能早日用上文本块,这样 sql 换行也就更美观了
- 面对太复杂的动态 sql 查询,jpa 没有好的解决办法,可以考虑引入 mybatis,限制只做单纯的查询操作,增删改操作全部使用 jpa 完成,这样也能可以做非常好的弥补。
- 也使用过 mybatis-plus,在 service 中使用 lambda wrapper,会让代码非常丑陋,dao 层的逻辑侵入到 service 中,非常不利于维护,后面将 wrapper 代码放到 mapper 的 default 方法解决了此问题;IService 也不是很好的实现,虽然可以抛弃不用;api 变动频繁,关于自动填充部分的接口变化太快,虽然官方文档有说明,但还是不太合理
- querydsl:jpa 可以很方便的引入 querydsl,曾经也使用过,可以编写类型安全的复杂查询,但是也做不到条件查询,而且代码可读性也不高,最终放弃