ElasticSearch
Elasticsearch 是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
一、基本概念
1、Index(索引)
类比 MySQL 的数据库
2、Type(类型)
类比 MySQL 的数据表
3、Document(文件)
类比 MySQL 的数据
4、倒排索引机制
二、Docker 安装
1、下载镜像文件
1 | |
2、创建实例
- 启动 ElasticSearch
1 | |
- 启动 kibana
1 | |
- 设置开机启动
1 | |
三、初步探索
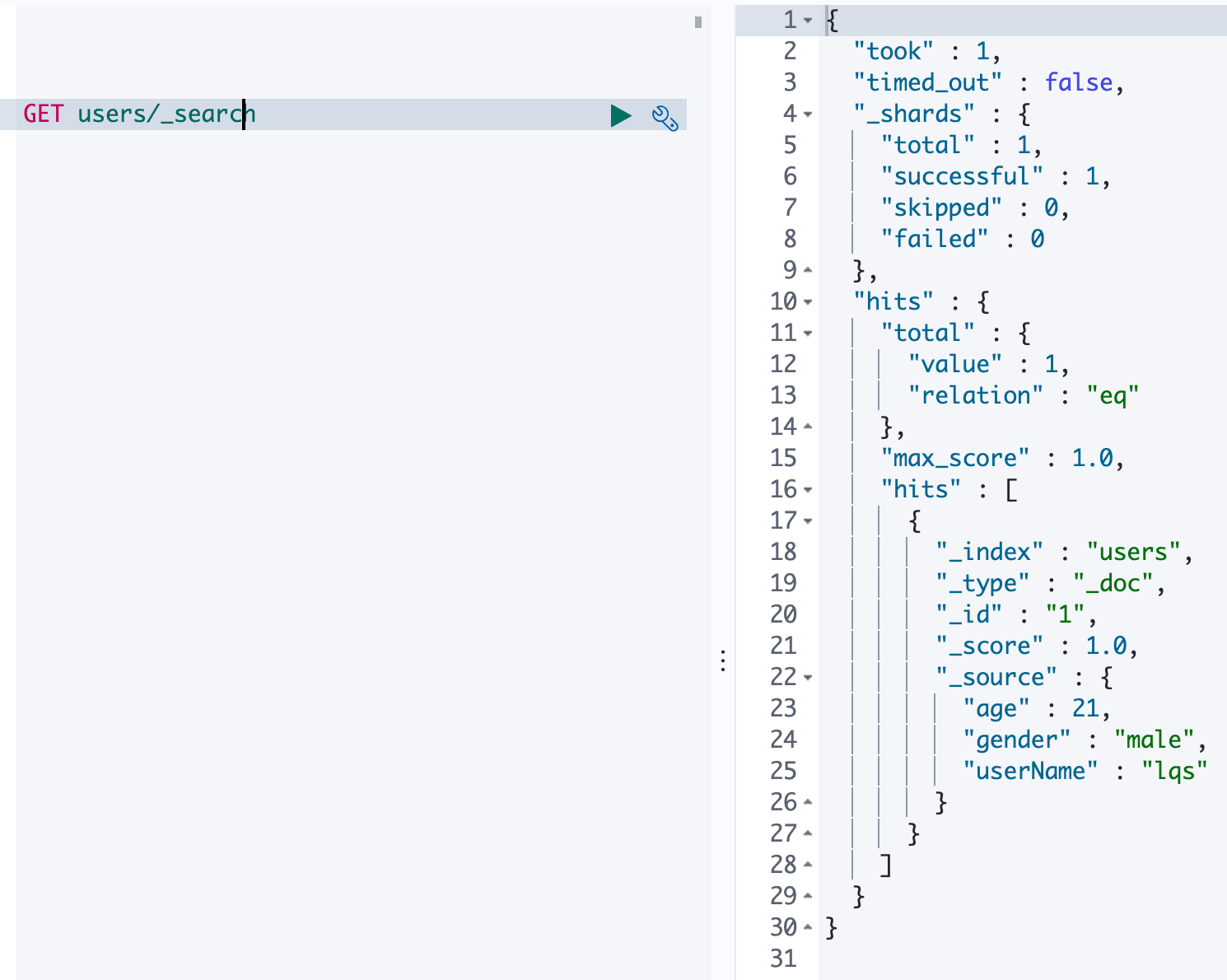
1、_cat
1 | |
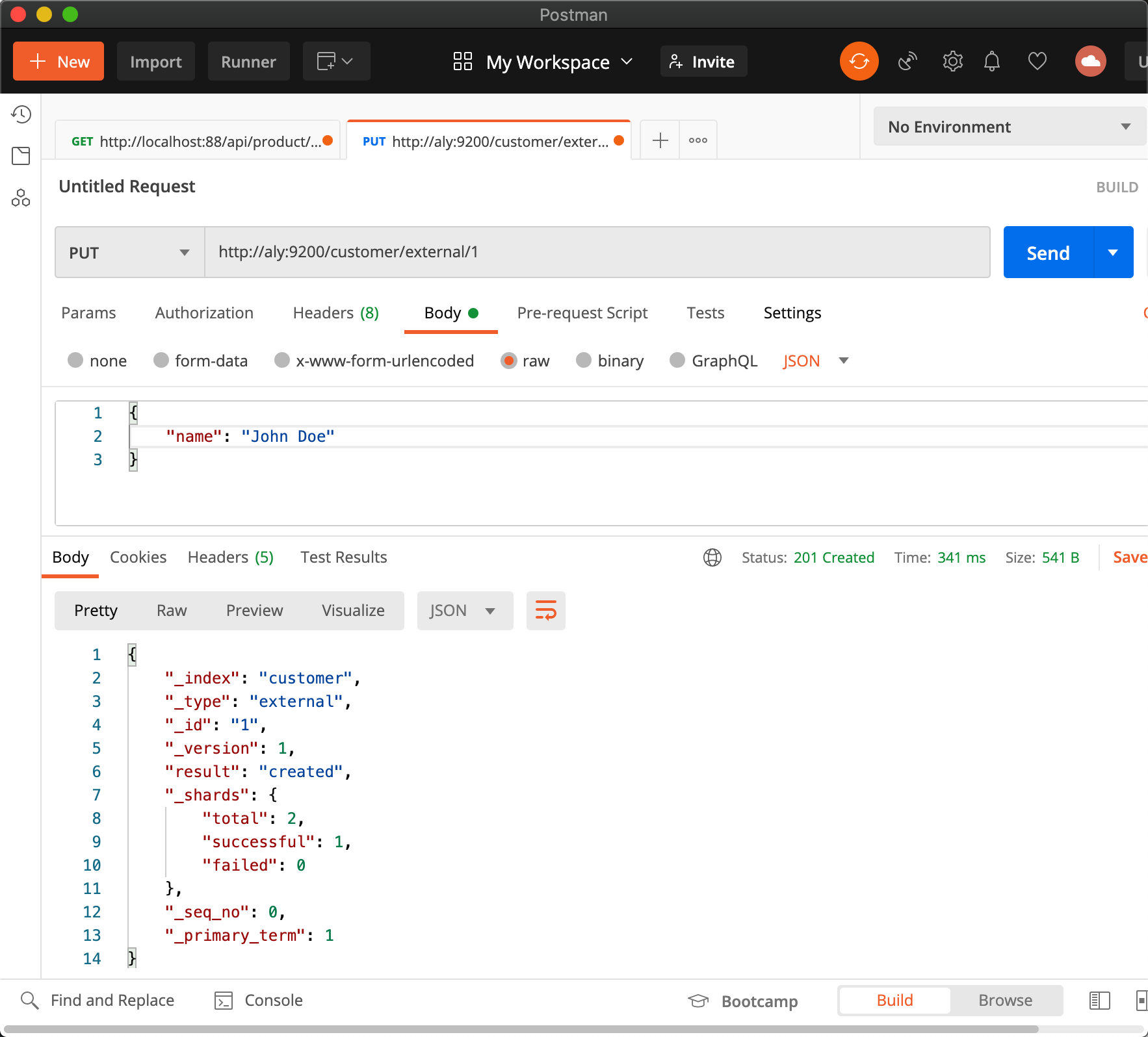
2、索引一个文档
- 保存一个数据,保存在哪个索引的哪个类型下,指定用那个唯一标识
PUT customer/external/1;在 customer 索引下的 external 类型下保存 1 号数据为
1 | |
1 | |
- PUT 和 POST 对比
项目 功能 id 一般用途 POST 新增 可以不指定 新增 PUT 新增/修改 必须指定 修改
1 | |
3、查看文档
1 | |

1 | |
4、更新文档
- 三种实现
1 | |
- 对比
- POST 会对比原文件数据,相同不会有操作,version 不增加
- PUT 总会更新数据且增加 version 字段
- 带_update 对比原数据一样就不进行任何操作
- 使用场景: - 大并发更新:不带 update - 大并发查询偶尔更新,带 update;对比更新,重新计算分配规则
带 update 不带 update POST body 带 doc 标签 PUT
5、删除文档或索引
1 | |
1 | |
注:elasticsearch 并没有提供删除类型的操作,只提供了删除索引和文档的操作
6、bulk 批量 API
- 语法
1 | |
- 例子
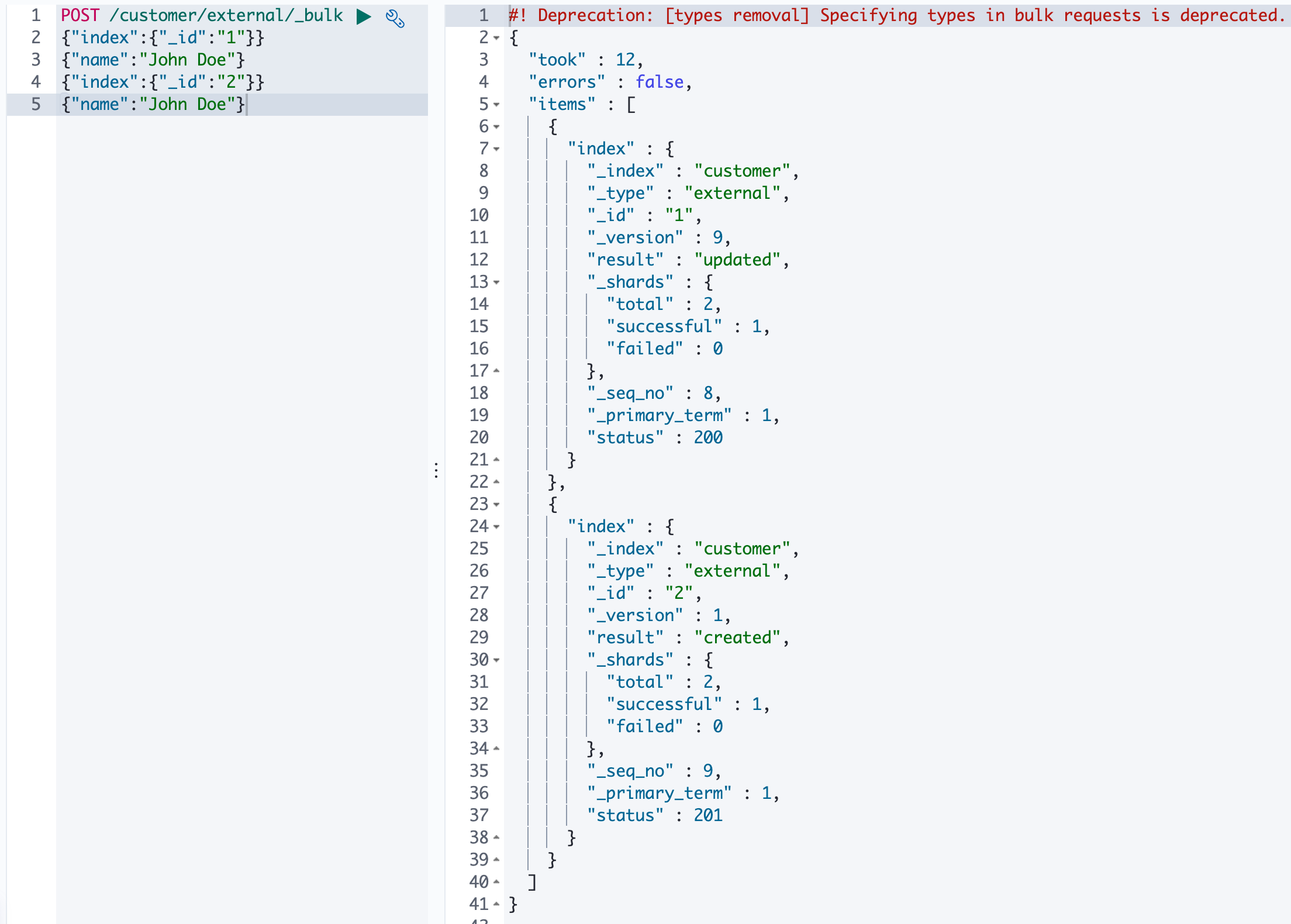
- 规则
1 | |
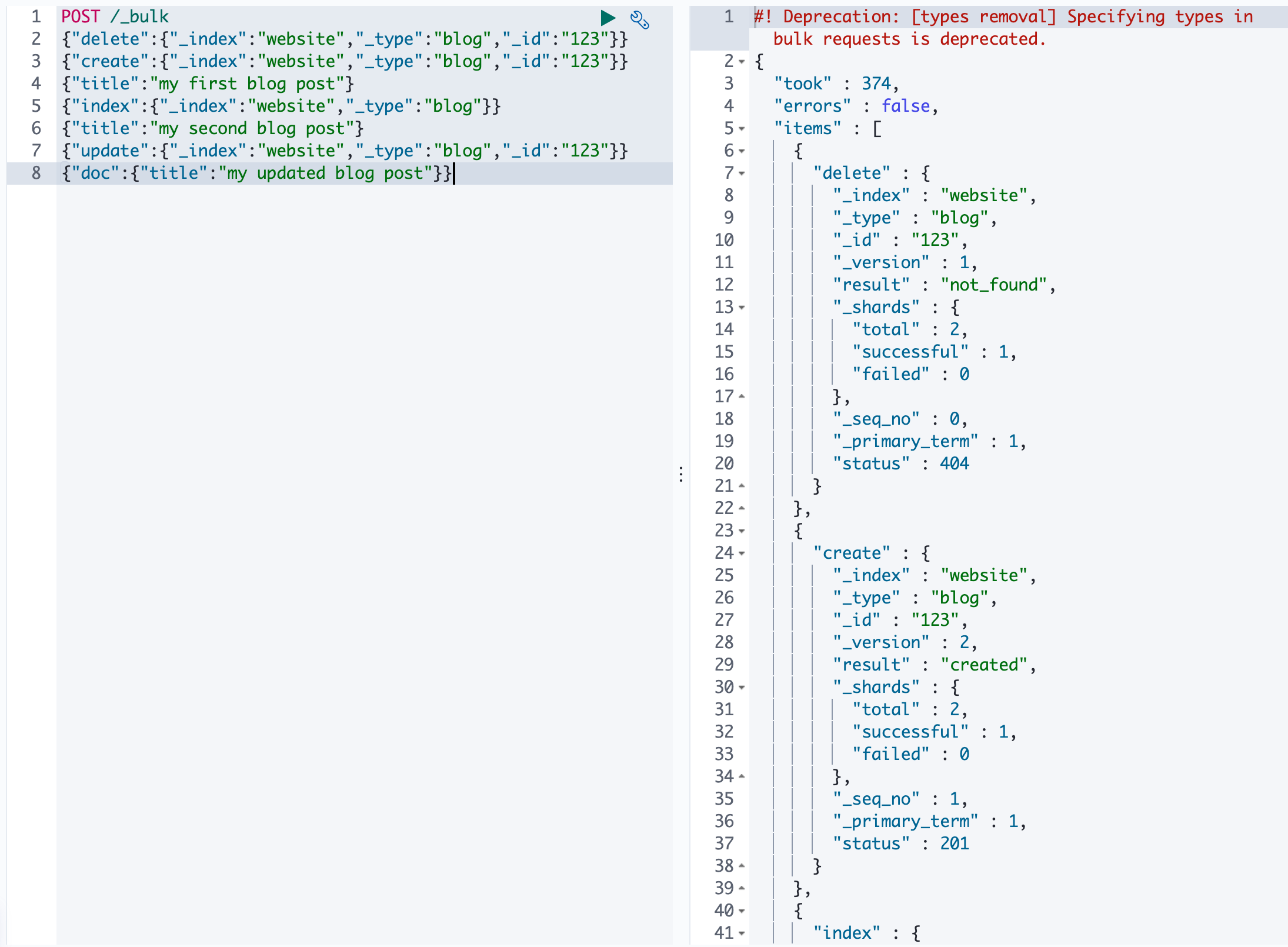
7、样本测试数据
测试数据,将所有数据保存,基于此进行测试

四、进阶检索
1、Search API
1、检索信息
ES 支持两种基本方式检索;
- 通过 REST request uri 发送搜索参数 (uri +检索参数);
1 | |
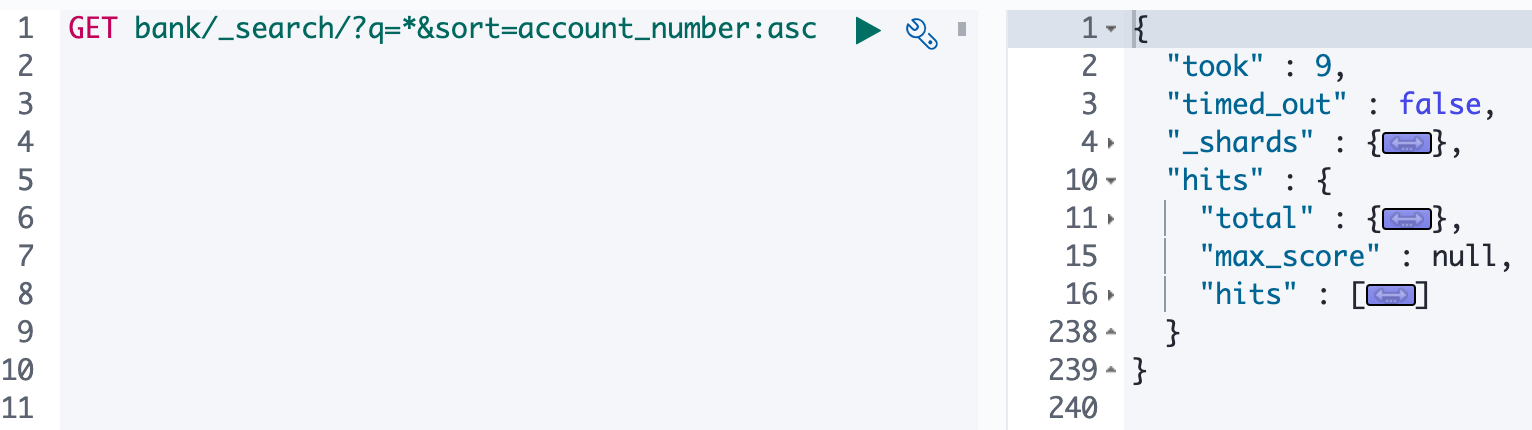
1 | |
- 通过 REST request body 来发送它们(uri+请求体);
1 | |
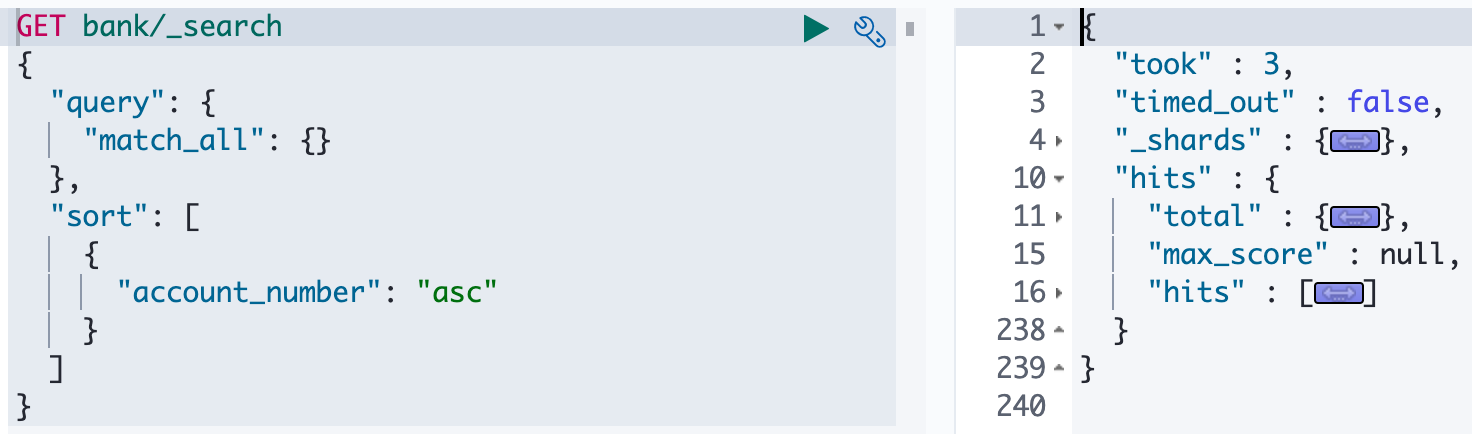
2、Query DSL
1、基本语法
Elasticsearch 提供了一个可以执行查询的 JSON 风格的 DSL。这个被称为 Query DSL,该查询语言非常全面。
- 一个查询语句的典型结构
1 | |
1 | |
1 | |
- match_all 查询类型【代表查询所有的所有】,es 中可以在 query 中组合非常多的查询类型完成复杂查询;
- 除了 query 参数之外,我们可也传递其他的参数以改变查询结果,如 sort,size;
- from+size 限定,完成分页功能;
- sort 排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准;
2、返回部分
- 规则
1 | |
- 例子
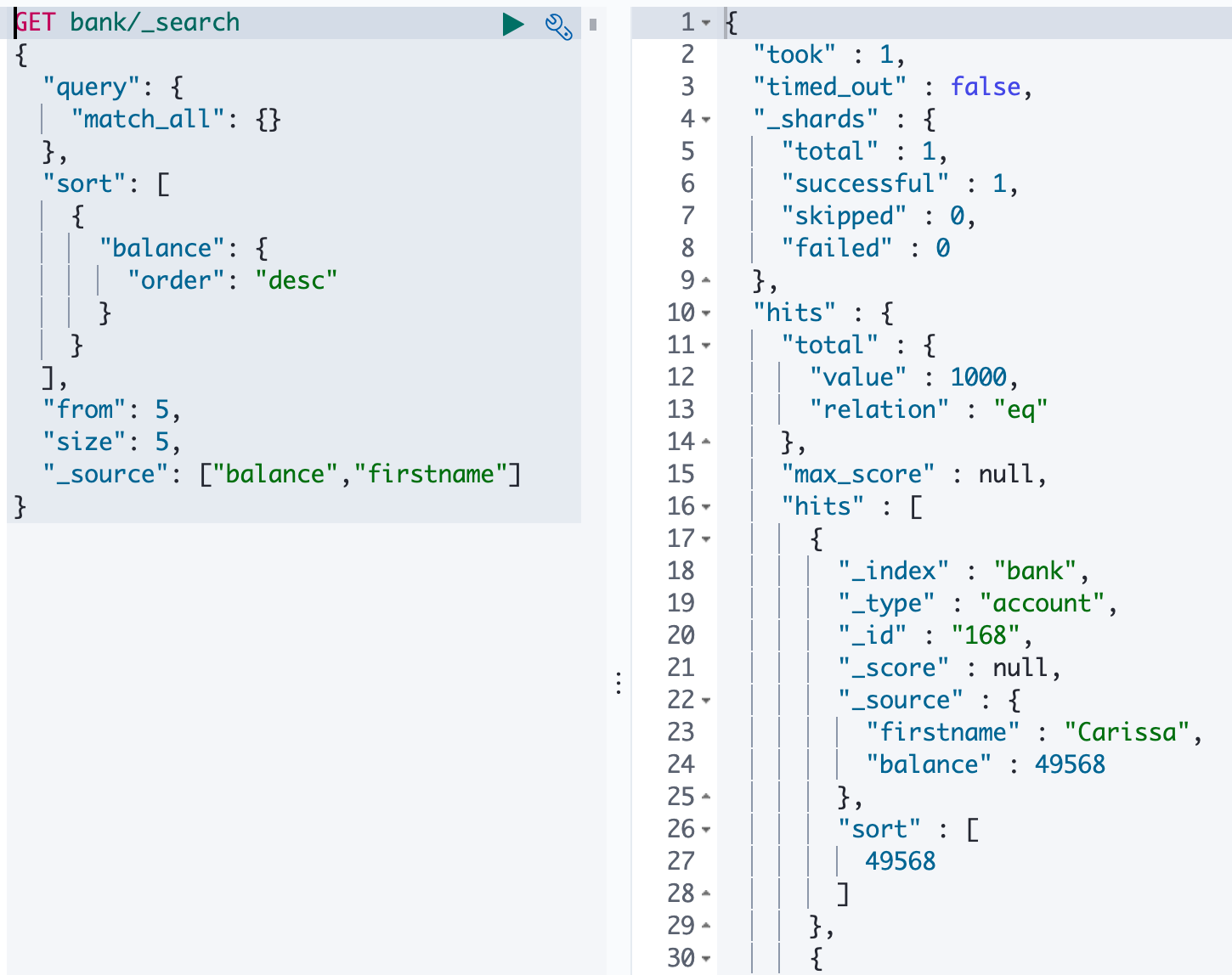
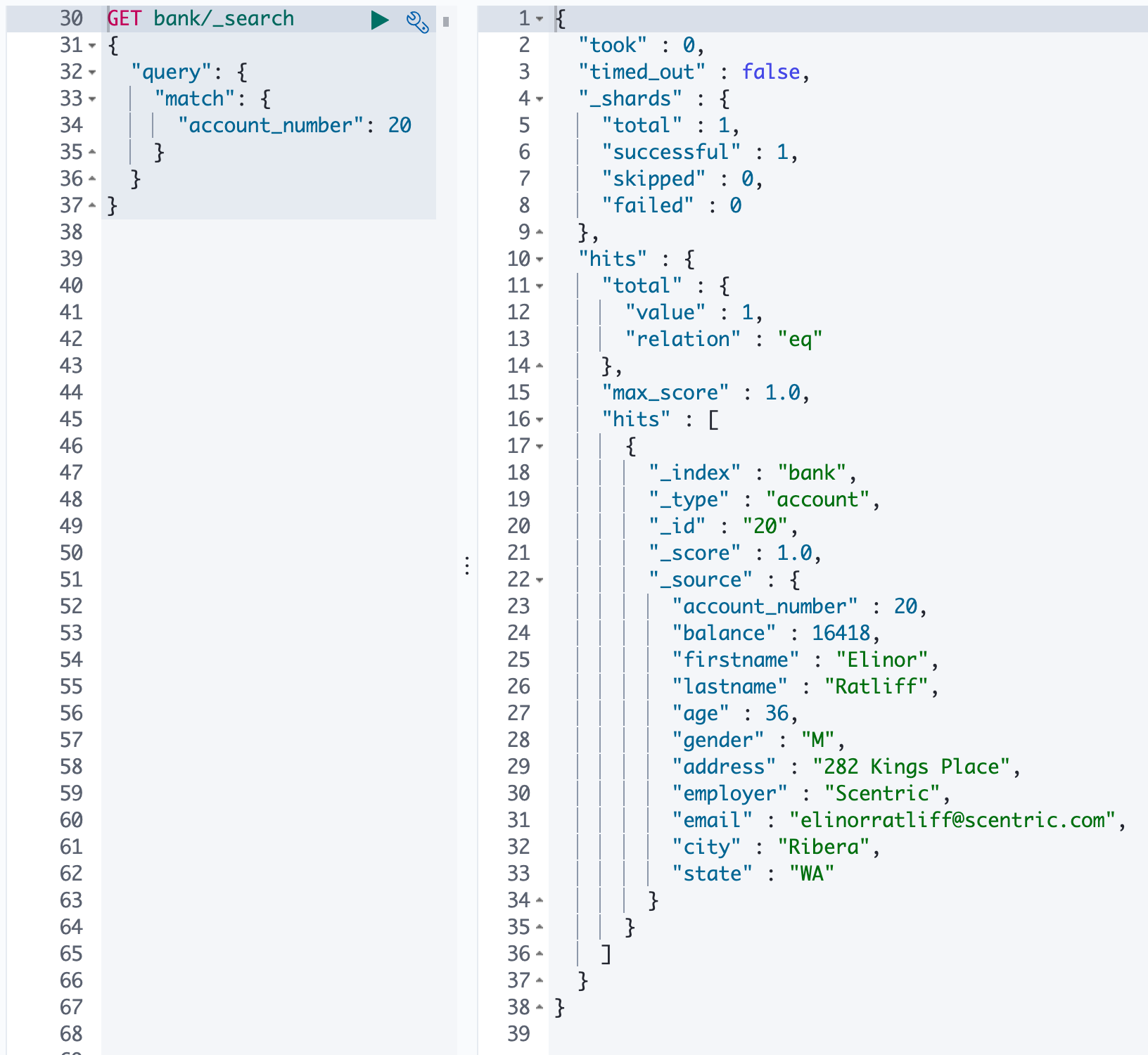
3、match - 匹配查询
全文检索,按照评分进行排序,依赖倒排索引
- 语法
1 | |
- 例子
4、match_phrase - 短句匹配
将需要匹配的值当成一整个单词(不分词)进行检索。
文本字段的匹配,使用 keyword,匹配的条件就是要显示字段的全部值,要进行精确匹配的。
match_phrase 是做短语匹配,只要文本中包含匹配条件,就能匹配到。
1 | |
5、multi_match - 多字段匹配
从几个字段中查询,相当于多个 match 叠加,会进行分词
1 | |
6、bool - 复合查询
复合查询,即可以进行嵌套,实现复杂的逻辑
1 | |
7、filter - 结果过滤
对结果进行过滤,相当于 MySQL 的
having。使用时不计算相关性得分。并不是所有的查询都需要产生分数,特别是哪些仅用于 filtering 过滤的文档。为了不计算分数,elasticsearch 会自动检查场景并且优化查询的执行。
1 | |
Each
must,should, andmust_notelement in a Boolean query is referred to as a query clause. How well a document meets the criteria in eachmustorshouldclause contributes to the document’s relevance score. The higher the score, the better the document matches your search criteria. By default, Elasticsearch returns documents ranked by these relevance scores.在 boolean 查询中,
must,should和must_not元素都被称为查询子句 。 文档是否符合每个“must”或“should”子句中的标准,决定了文档的“相关性得分”。 得分越高,文档越符合您的搜索条件。 默认情况下,Elasticsearch 返回根据这些相关性得分排序的文档。The criteria in a
must_notclause is treated as a filter. It affects whether or not the document is included in the results, but does not contribute to how documents are scored. You can also explicitly specify arbitrary filters to include or exclude documents based on structured data.
“must_not”子句中的条件被视为“过滤器”。它影响文档是否包含在结果中, 但不影响文档的评分方式。 还可以显式地指定任意过滤器来包含或排除基于结构化数据的文档。
8、term - 匹配查询
和 match 一样。匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用 term。
1 | |
9、aggregation - 执行聚合
从数据中分组和提取数据。
最简单的聚合方法大致等于 SQL Group by 和 SQL 聚合函数。在 elasticsearch 中,执行搜索返回 this(命中结果),并且同时返回聚合结果,把以响应中的所有 hits(命中结果)分隔开的能力。这是非常强大且有效的,你可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一次简洁和简化的 API 啦避免网络往返。
3、Mapping
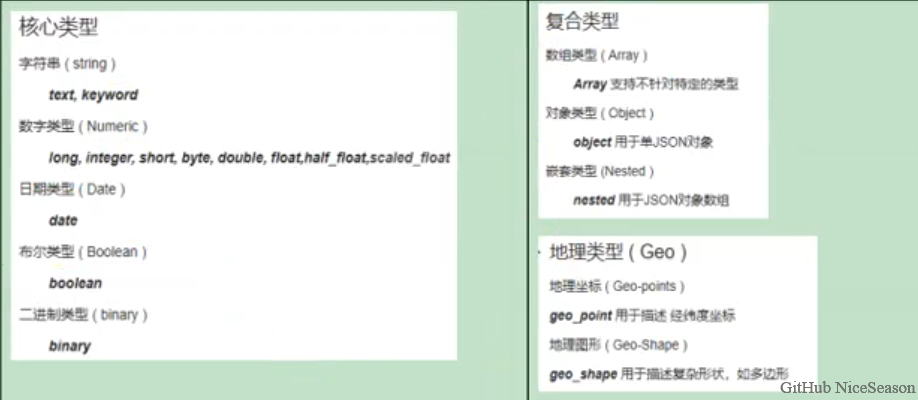
1、字段类型
2、映射
Maping 是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的
3、新版本改变
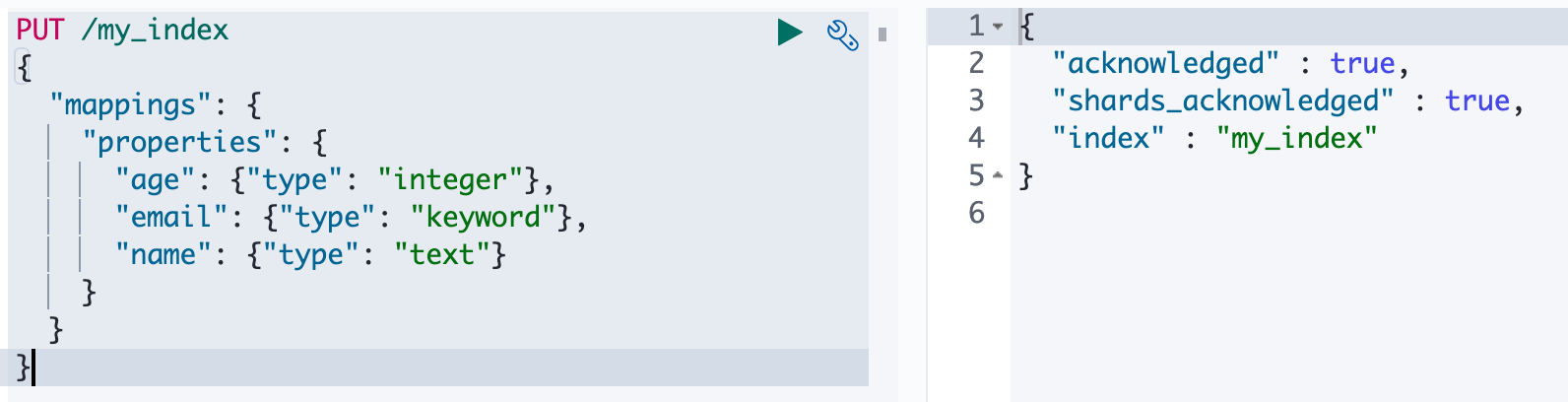
创建映射
1 | |
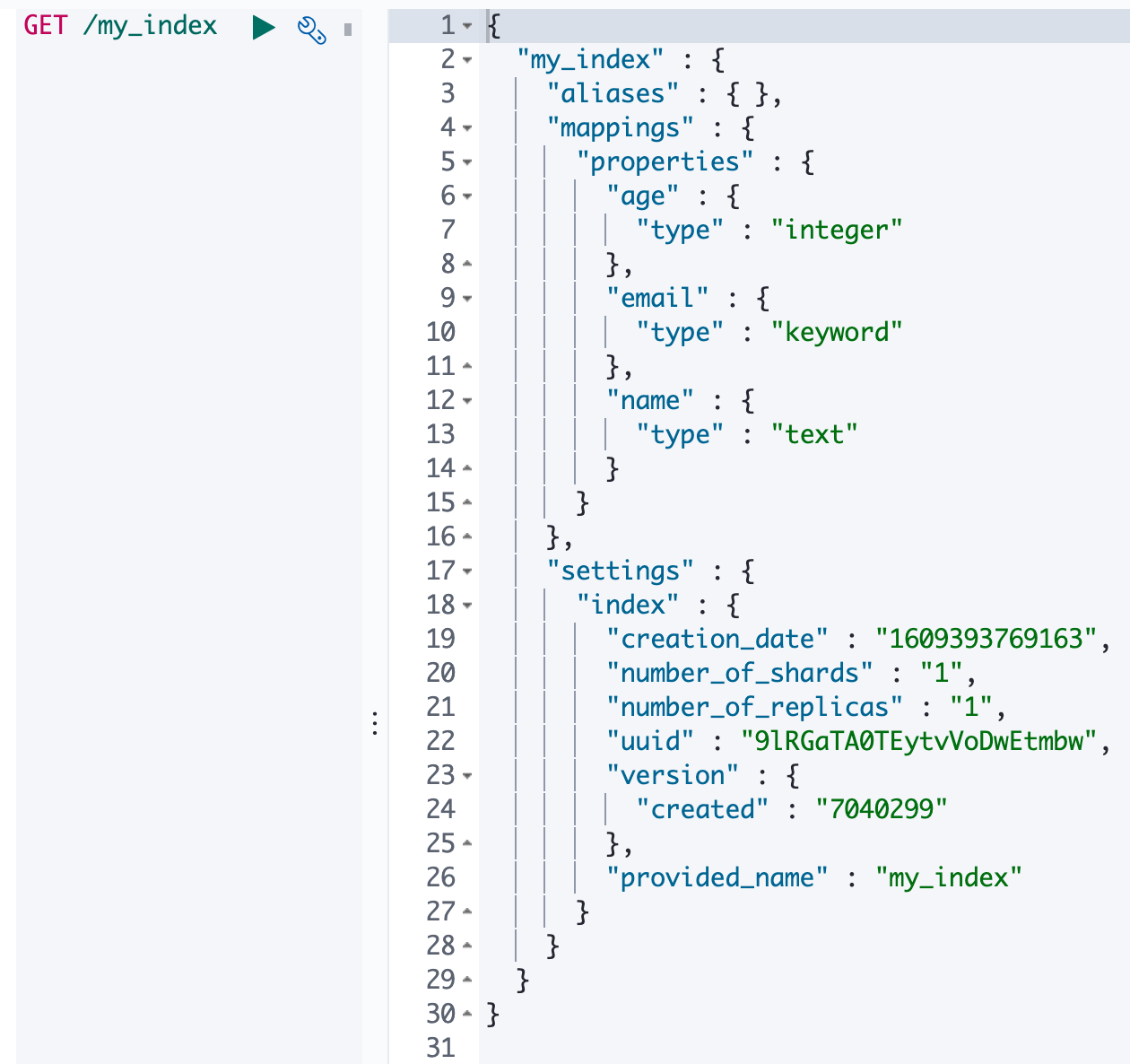
查看映射
添加新字段映射
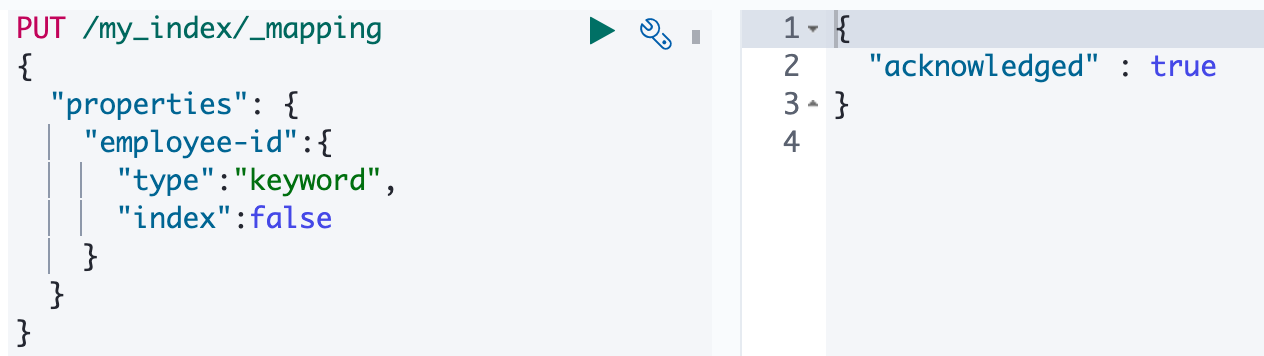
更新映射
对于已经存在的字段映射,我们不能更新。更新必须创建新的索引,进行数据迁移。
数据迁移
1 | |
更多详情见: 数据迁移
4、分词
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立的单词),然后输出 tokens 流。
例如:whitespace tokenizer 遇到空白字符时分割文本。它会将文本“Quick brown fox!”分割为[Quick,brown,fox!]。
该 tokenizer(分词器)还负责记录各个 terms(词条)的顺序或 position 位置(用于 phrase 短语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start(起始)和 end(结束)的 character offsets(字符串偏移量)(用于高亮显示搜索的内容)。
elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
关于分词器: 分词器
- 使用
1 | |
1、安装 ik 分词器
1 | |
2、测试
- 使用默认分词器
1 | |
1 | |
- 使用智能分词器
1 | |
1 | |
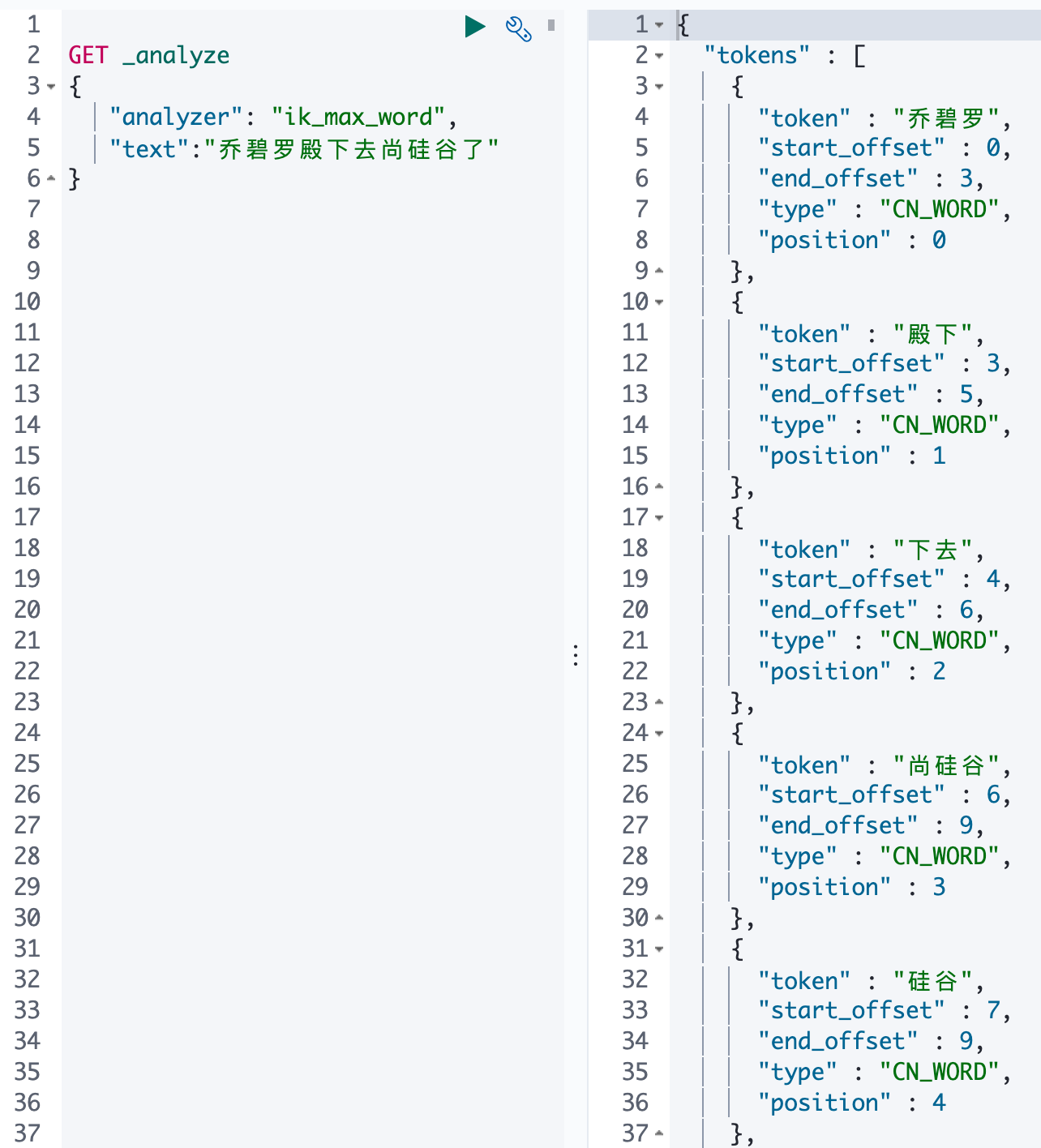
- 使用 max 分词器
1 | |
输出结果:
1 | |
3、自定义词库
安装 nginx
1 | |
添加字典
1 | |
修改配置
1 | |
使用
- 先重启 es
五、ElasticSearch-Rest-Client
有几种办法
- 9300: TCP
- spring-data-elasticsearch:transport-api.jar;
- springboot 版本不同,ransport-api.jar 不同,不能适配 es 版本
- 7.x 已经不建议使用,8 以后就要废弃
- 9200: HTTP
- jestClient: 非官方,更新慢;
- RestTemplate:模拟 HTTP 请求,ES 很多操作需要自己封装,麻烦;
- HttpClient:同上;
- Elasticsearch-Rest-Client:官方 RestClient,封装了 ES 操作,API 层次分明,上手简单;
最终选择 Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client);
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
1、SpringBoot 整合 ES
- 1、maven 依赖
1 | |
- 2、yml 配置
1 | |
- 3、配置类
1 | |
- 4、测试使用
1 | |