程序=算法+数据结构。可见算法和数据结构的重要性。该课程来自 bilibili分享
一、数据结构基本概念
1、数据结构研究内容
- 抽象为数学模型
- 分析问题
- 提取操作对象
- 找出操作对象间关系
- 用数学语言描述
- 设计算法
- 编程、调试、 运行
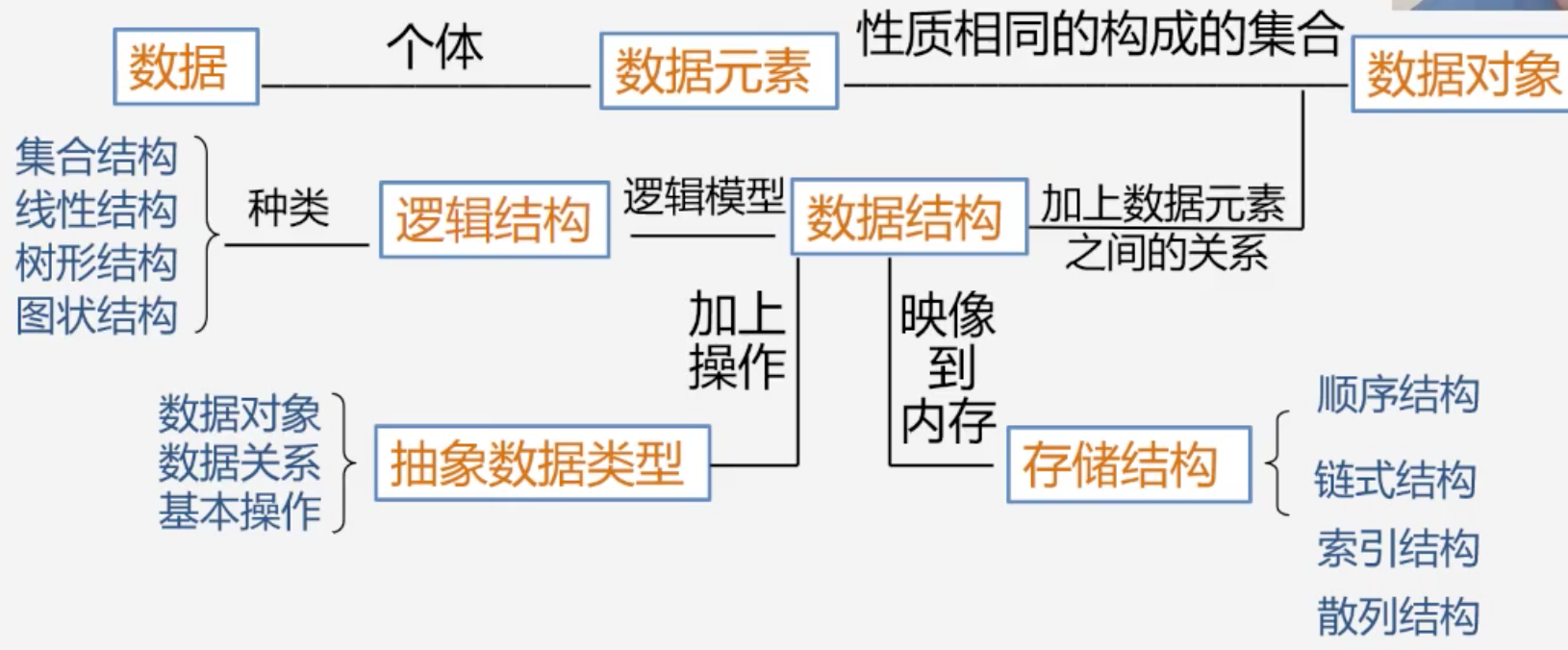
2、基本概念和术语
- Data
- 数据对象
- 数据结构
- 逻辑结构
- 划分方式一
- 线性结构:线性表、栈、队列、串
- 非线性结构: 树、图
- 划分方式二
- 物理结构(存储结构)
3、抽象数据类型与表示
4、算法与算法分析
算法:解决问题的一种方法或一个过程
程序 = 数据结构+ 算法
1、算法特性
2、算法设计要求
- 正确性
- 不含语法错误
- 对于几组输入得出满足条件的结果
- 对于精心选择、典型、苛刻的数据能得到满足的输出
- 一切合法输出都能得到满足的输出
- 可读性
- 健壮性
- 输出非法数据会做出恰当处理
- 处理出错不会中断执行,会返回一个表示错误的值
- 高效性
3、算法时间效率的度量
- 事前分析
- 对资源消耗低估算

- 一般只比较数量级
- 事后统计
- 将算法实现,测算时间空间消耗
- 缺点
- 编写实现算法花费时间经历多
- 实验结果依赖于计算机当前硬件,掩盖算法优劣
二、基本数据结构
1、线性结构
1、线性表(Linear List)
由 n(n≥0)个数据元素组成的有限序列
- n 定义表的长度
- n=0 时称为空表
- 数据元素只是抽象符号,具体含义在不同情况下可以不同
逻辑特征
- 非空线性表有且仅有一个开始节点,他没有直接前趋,仅有一个直接后继
- 有且仅有一个终端节点,他没有直接后继,有且仅有一个直接前趋
- 其余内部节点,都有且仅有一个直接前趋和一个直接后继
类型定义

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| # 构造一个空的线性表L
InitList(&L)
# 销毁线性表L(初始条件:L已存在)
DestoryList(&L)
# 将线性表重置为空(初始条件:L已存在)
ClearList(&L)
# L为空返回TRUE,否则返回false(初始条件:L已存在)
ListEmpty(L)
# 返回线性表L的数据元素个数(初始条件:L已存在)
ListLength(L)
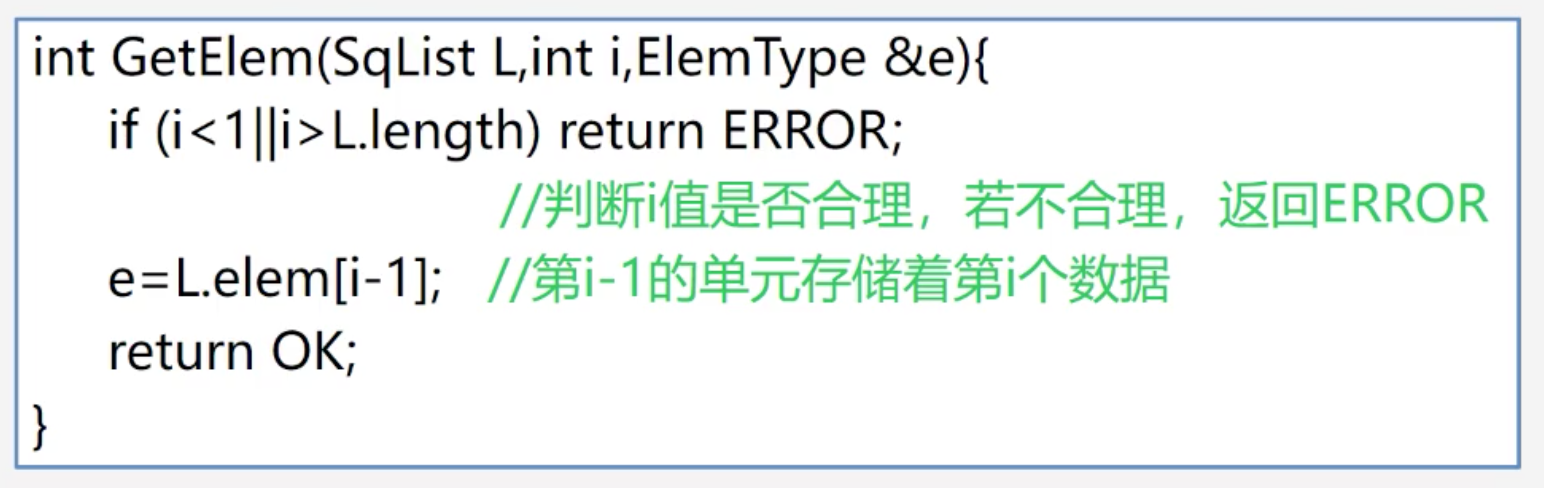
# 用e返回L中第i个数据元素(初始条件:L已存在,1 ≤ i ≤ ListLength(L))
GetElem(L,i,&e)
# 返回L中第一个与e满足compare()的数据元素的位置,不存在就返回0(初始条件:L已存在,compare是判定函数)
LocateElem(L,e,compare())
# 若cur_e是L中的元素且不是第一个,用pre_e返回它的前驱;否则操作失败,pre_e无意义(初始条件:L已存在)
PriorElem(L,cur_e,&pre_e)
# 若cur_e是L中元素且不是最后一个,用next_e返回它的后继;否则操作失败,next_e无意义(初始条件:L已存在)
NextElem(L,cur_e,&next_e)
# 在L的第i个位置之前插入新数据元素e,L长度+1(初始条件:L已存在,1 ≤ i ≤ ListLength(L))
ListInsert(&L,i,e)
# 删除L的第i个元素,用e返回其值,L长度-1(初始条件:L已存在,1 ≤ i ≤ ListLength(L))
ListDelete(&L,i,&e)
# 依次对线性表每个元素调用visited()(初始条件:L已存在)
ListTraverse(&L, visited())
|
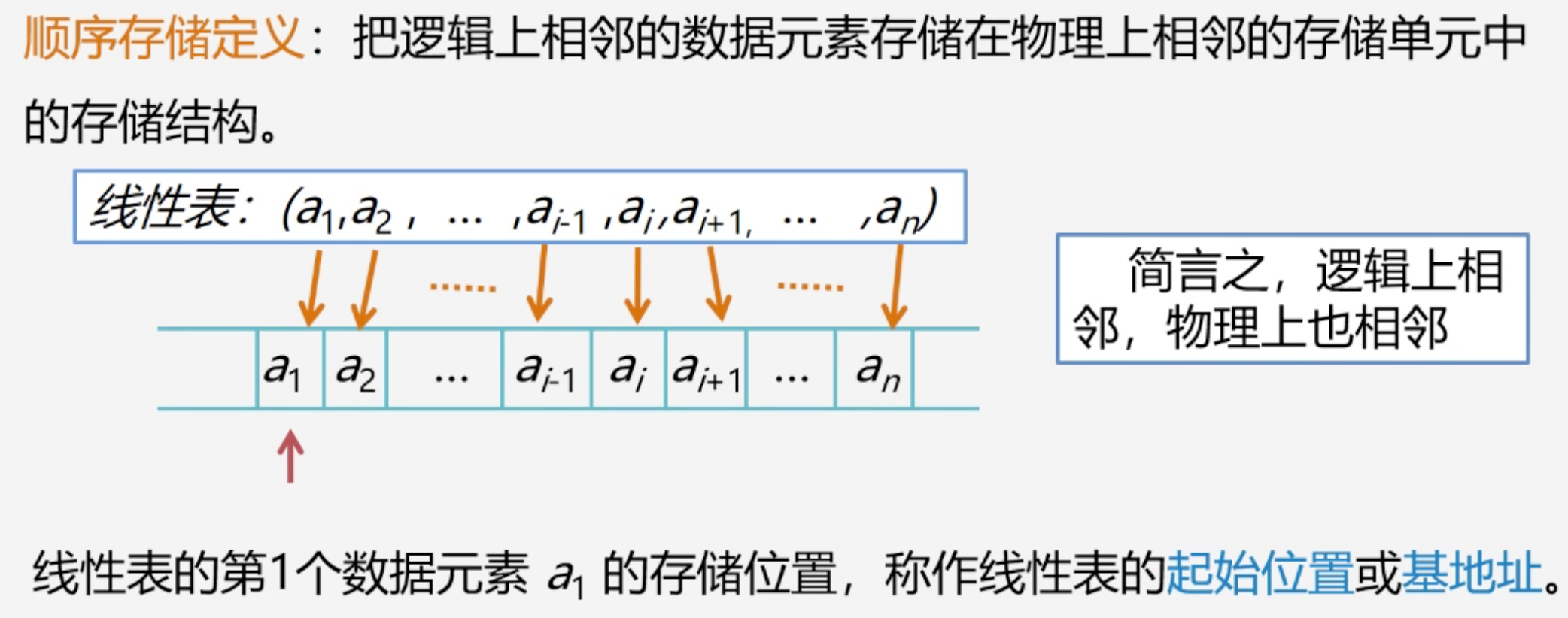
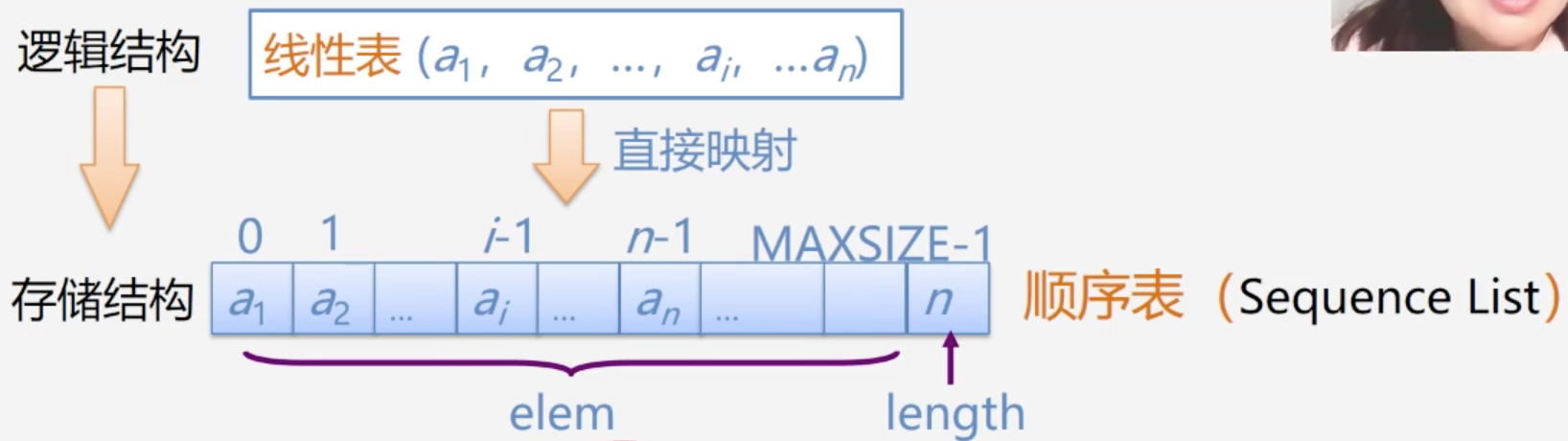
顺序表示和实现
定义:把逻辑上相邻的数据元素存储在物理上相邻的存储单元中
- 占用一片连续的存储空间
- 知道某个元素存储位置就可计算其他元素的存储位置

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # 数组静态分配
typedef struct {
# 具体情况具体选择ElemType
ElemType data[MaxSize];
int length;
}SqList;
# 数组动态分配
typedef struct{
ElemType *data;
int length;
}SqList;
SqList L;
# 分配内存
L.data = (ElemType*)malloc(sizeof(ElemType)*MaxSize)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
malloc(m)
sizeof(x)
free(p)
new 类型T(初值列表)
delete p
int i = 5;
int &j = i;
i = 7;
j是应用类型
|












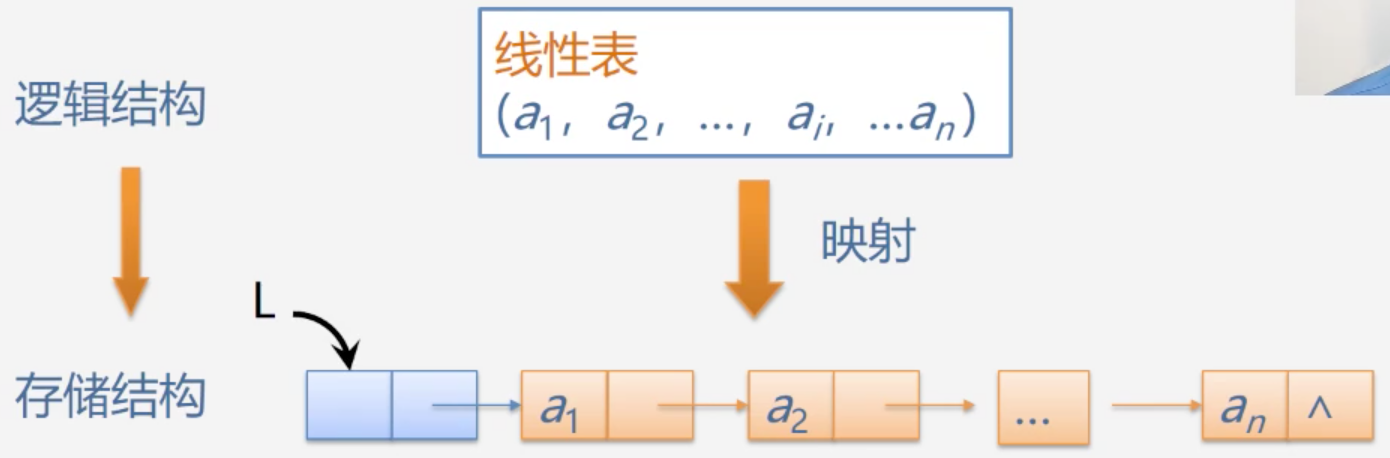
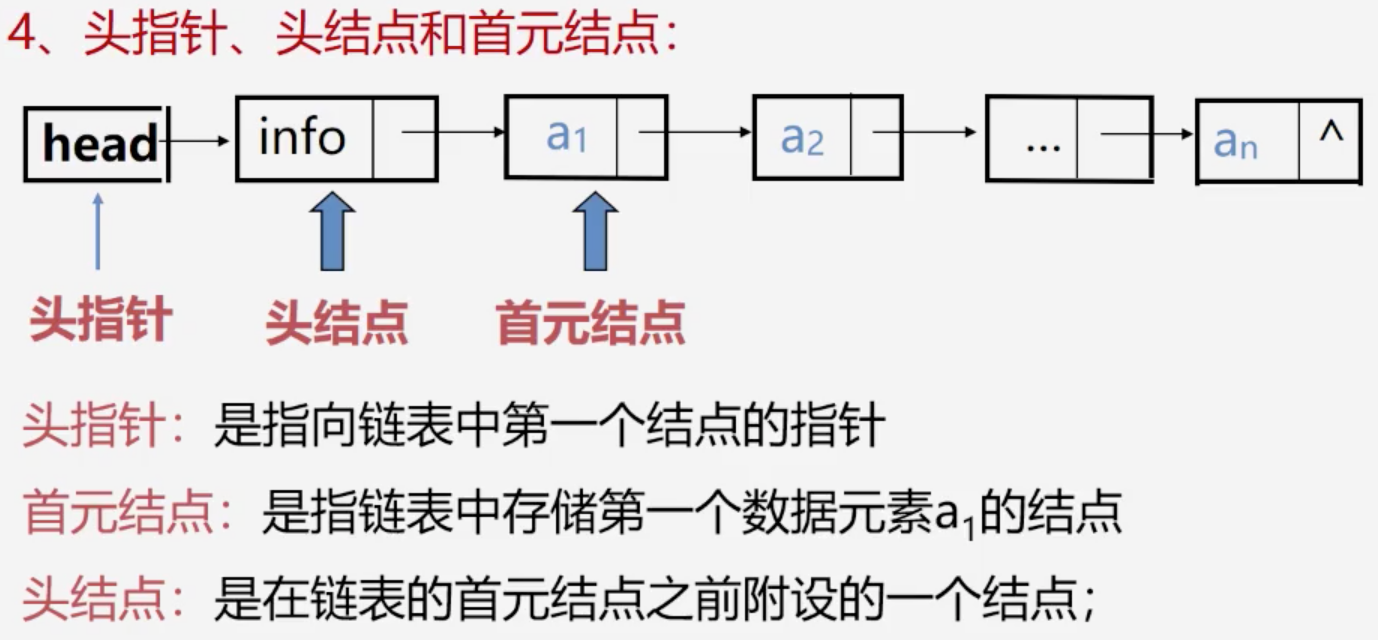
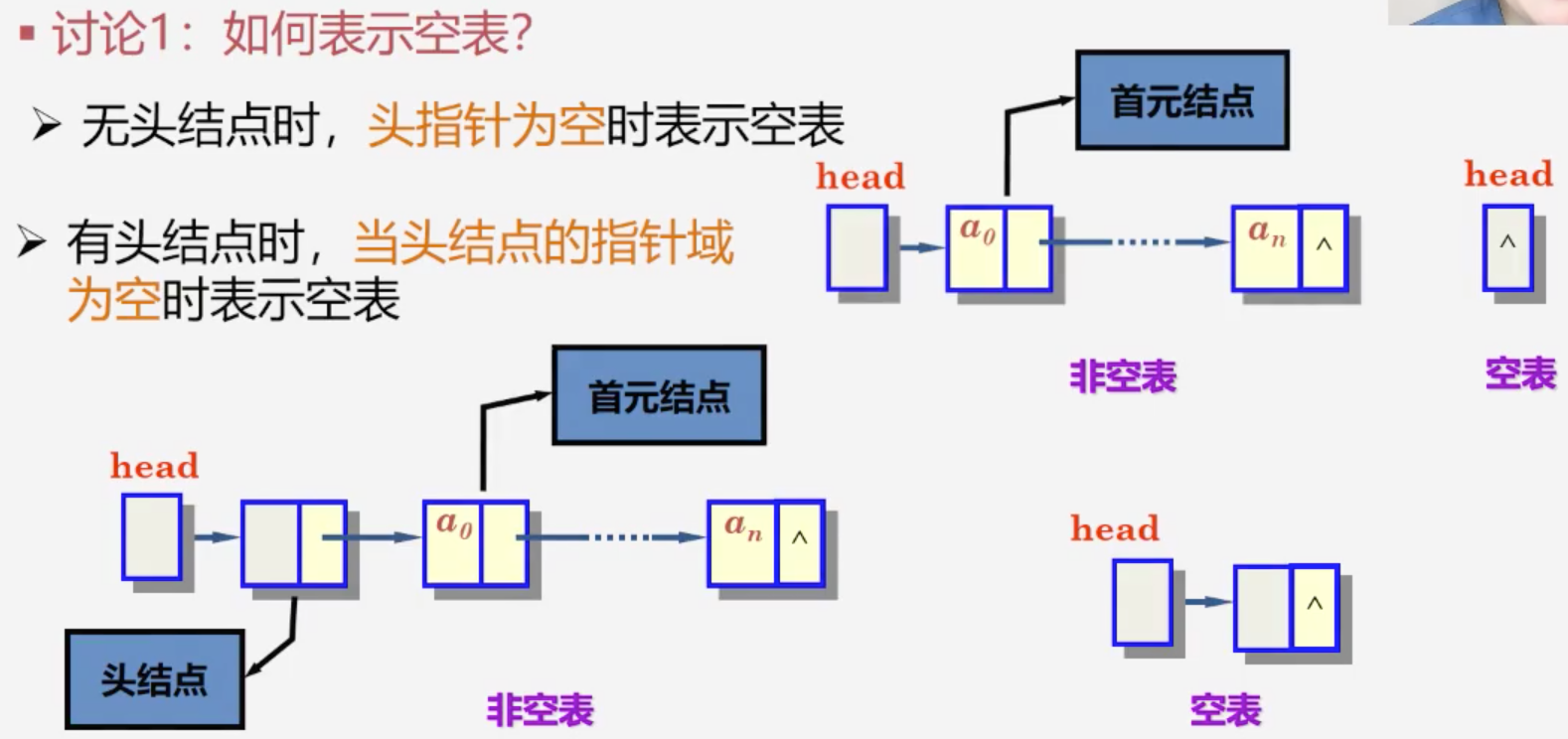
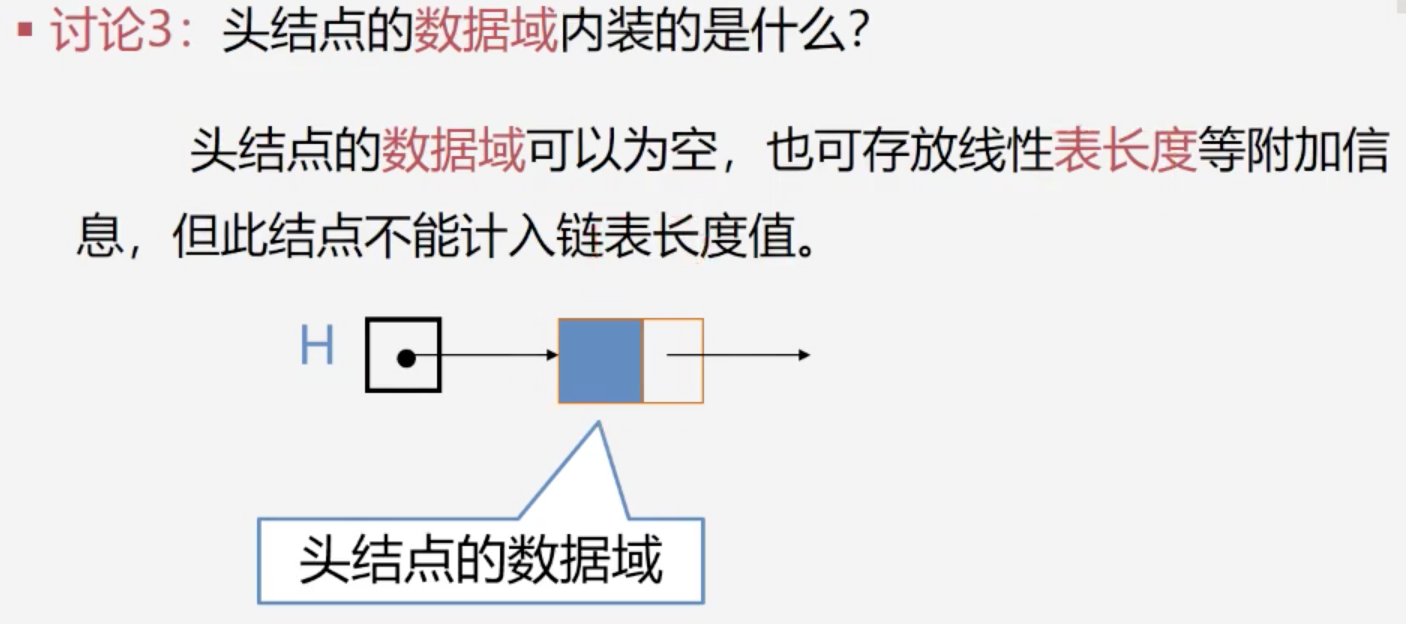
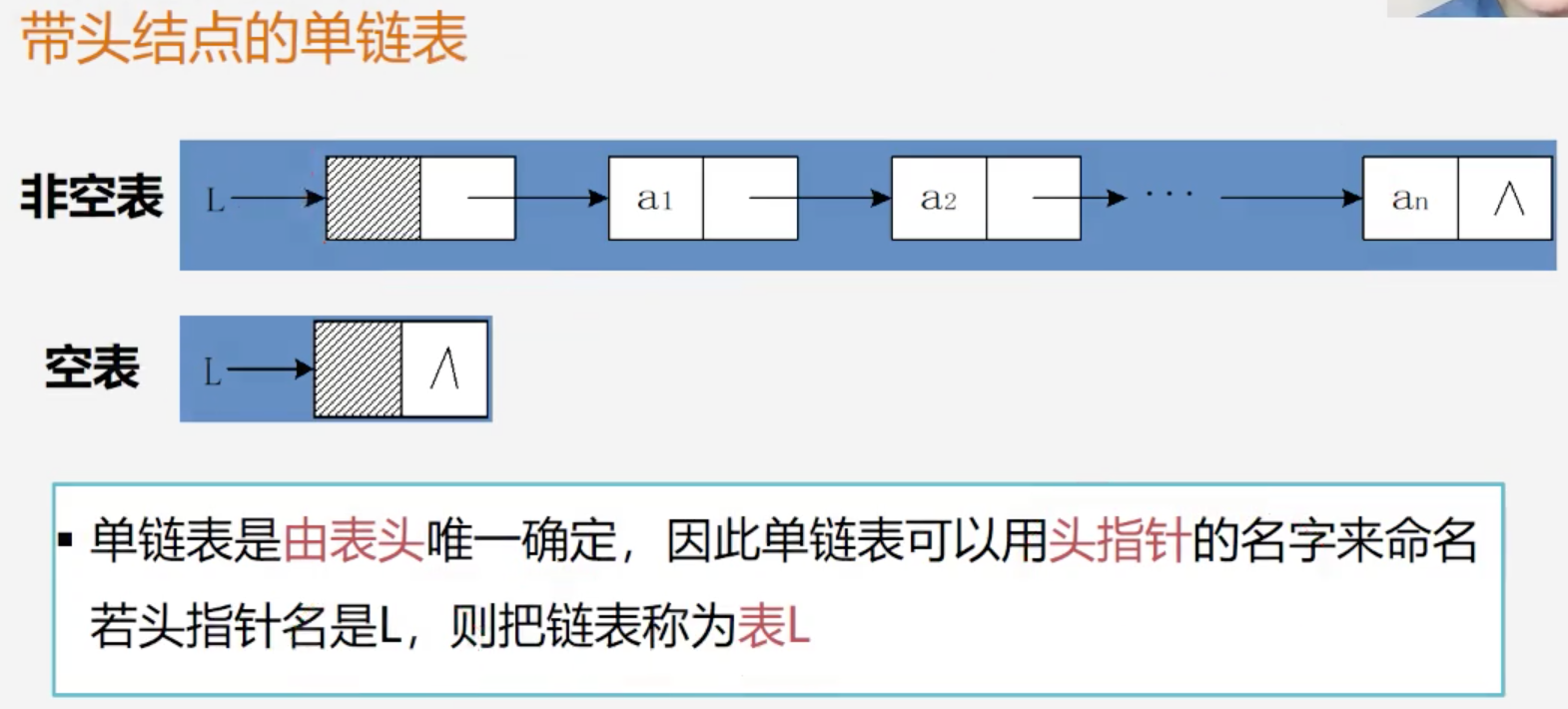
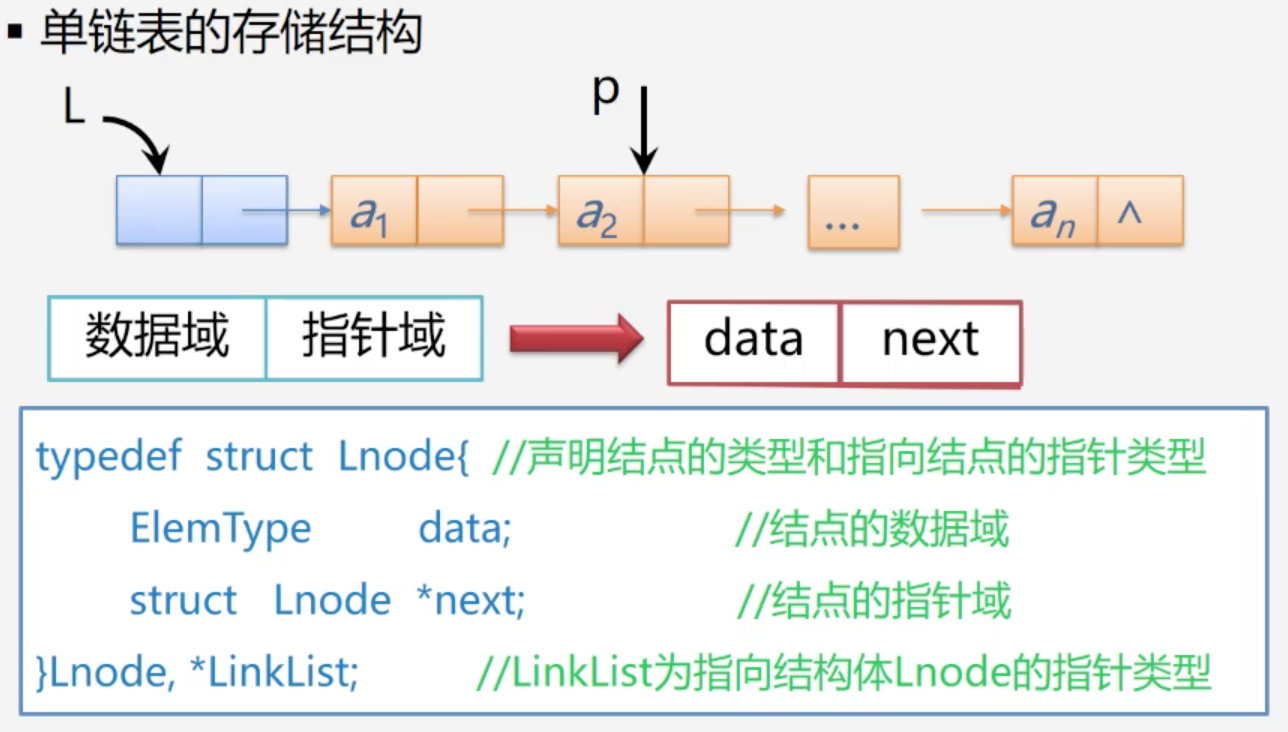
链式表示和实现



1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
|
Status LinkList_L(LinkList &L){
L = new LNode;
L->next = null;
return OK;
}
int ListEmpty(LinkList L){
if(L->next)
return 0;
else
return 1;
}
Status DestoryList_L(LinkList &L){
Lnode *p;
while(L){
p = l;
L =L->next;
delete p;
}
}
Status ClearList(LinkList &L){
Lnode *p,*q;
p = L->next;
while(p){
q = p->next;
delete p;
p = q;
}
L->next = null;
return OK;
}
int ListLength_L(LinkList L){
LinkList p;
p = l->next;
i = 0;
while(p){
i++;
p = p->next;
}
return i;
}
Status GetElem_L(LinkList L,int i,ElemType &e){
p = l->next;j = 1;
while(p && j<1){
p = p->next;++j;
}
if(!p || j>i) return ERROR;
e = p->data
return OK;
}
Lnode *LocateElem_L(LinkList L,ElemType e){
p = L->next;
while(p && p->data != e)
p = p->next;
return p:
}
int LocateElem_L(LinkList L,ElemType e){
p = L->next;j=1;
while(p && p->data != e){
p = p->next;
j++;
}
if(p) return j;
else return 0;
}
Status ListInsert_L(LinkList &L,int i,ElemType e){
p = L;j = 0;
while(p && j < i-1) {p = p->next; j++;}
if(!p || j > i-1) return ERROR;
s = new LNode;
s->data = e;
s->next = p->next;
p->next = s;
return OK;
}
Status ListDelete_L(LinkList &L,int i,ElemType e){
p = L;j = 0;
while(p && j < i-1) {p = p->next; ++j;}
if(!p->next || j > i-1) return ERROR;
q = p->next;
p->next = q->next;
e = q->data;
delete q;
return OK;
}
void CreateList_H(LinkList &L,int n){
L = new LNode;
L->next = null;
for(int i = n; i > 0; --i){
p = new LNode;
cin >> p->next;
p->next = L->next;
L->next = p;
}
}
void CreateList_R(LinkList &L,int n){
L = new LNode;
L->next = null;
r = L;
for(int i = 0; i < n; i++){
p = new LNode; cin >> p->next;
p->next = null;
r->next = p;
r = p;
}
}
|
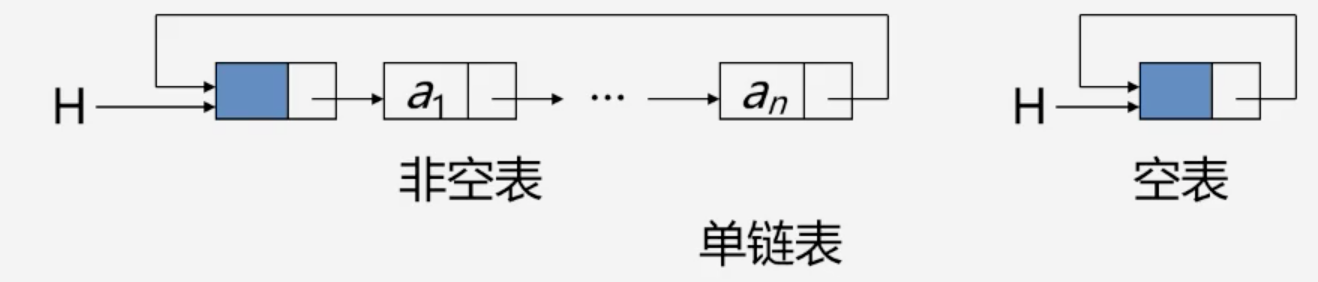
循环链表:是一种头尾相连的链表
- 从表中任意一节点出发均可以找到其他节点
- 查找比单链表更方便
1
2
3
4
5
6
7
| LinkList Connect(LinkList a,LinkList b){
p = a->next;
a->next = b->next->next;
delete b->next;
b->next = p;
return b;
}
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
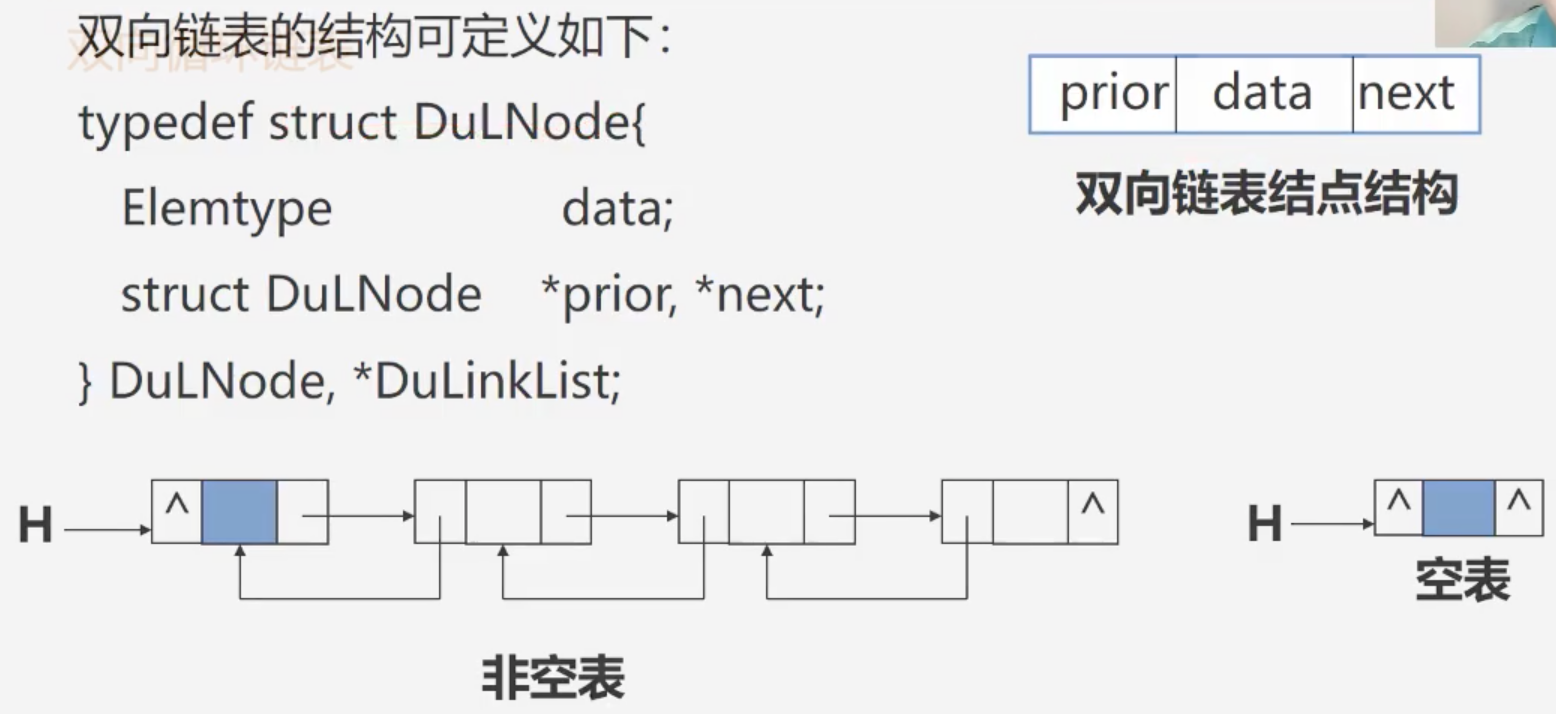
void ListInsert_Dul(DuLinkList &L,int i,ElemType e){
if(!(p = GetElemP_DuL(L,i))) return ERROR;
s = new DuLNode; s->data = e;
s->prior = p->prior; p->prior->next = s;
s->next = p; p->prior = s;
return OK;
}
void ListDelete_DuL(DuLink &L,int i,Elemtype &e){
if(!(p = getElemP_DuL(L,i))) return ERROR;
e = p->data;
p->prior->next = p->next;
p->next->prior = p->prior;
free(p);
return OK;
}
|
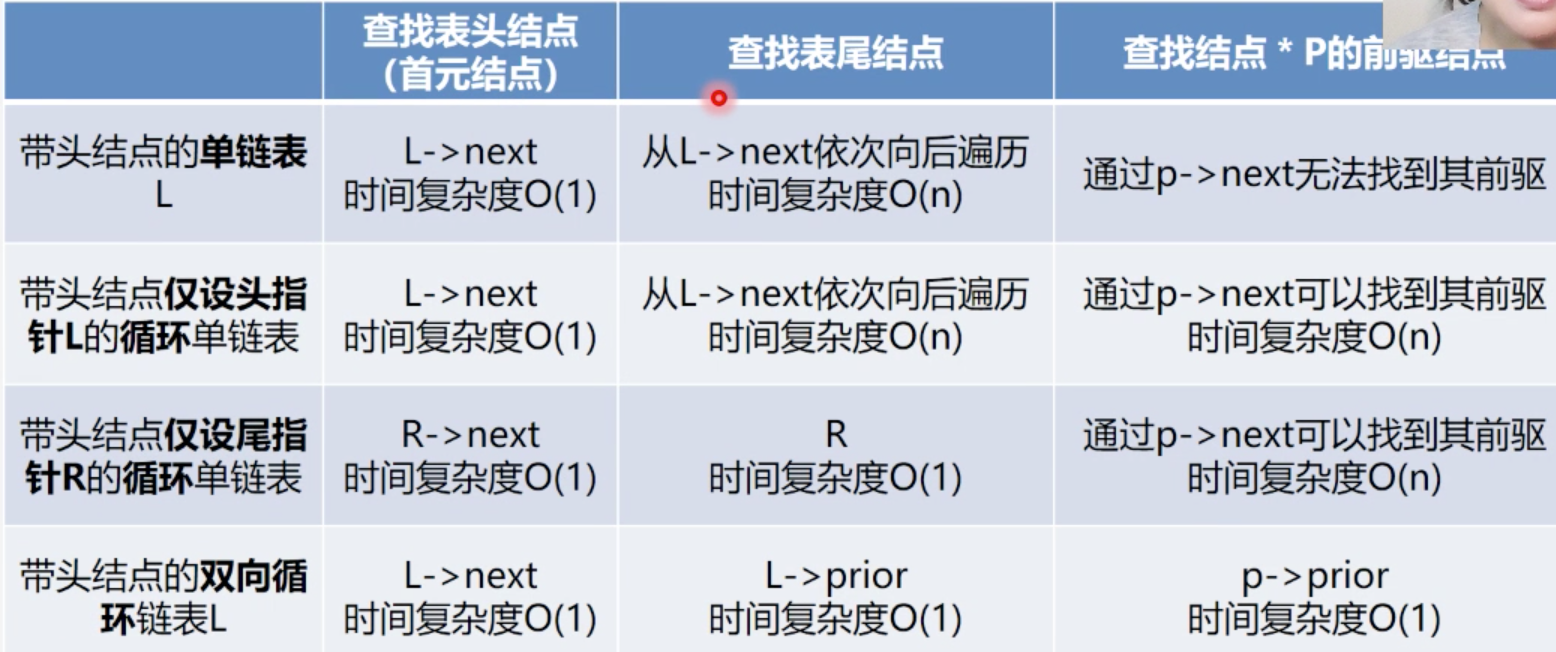
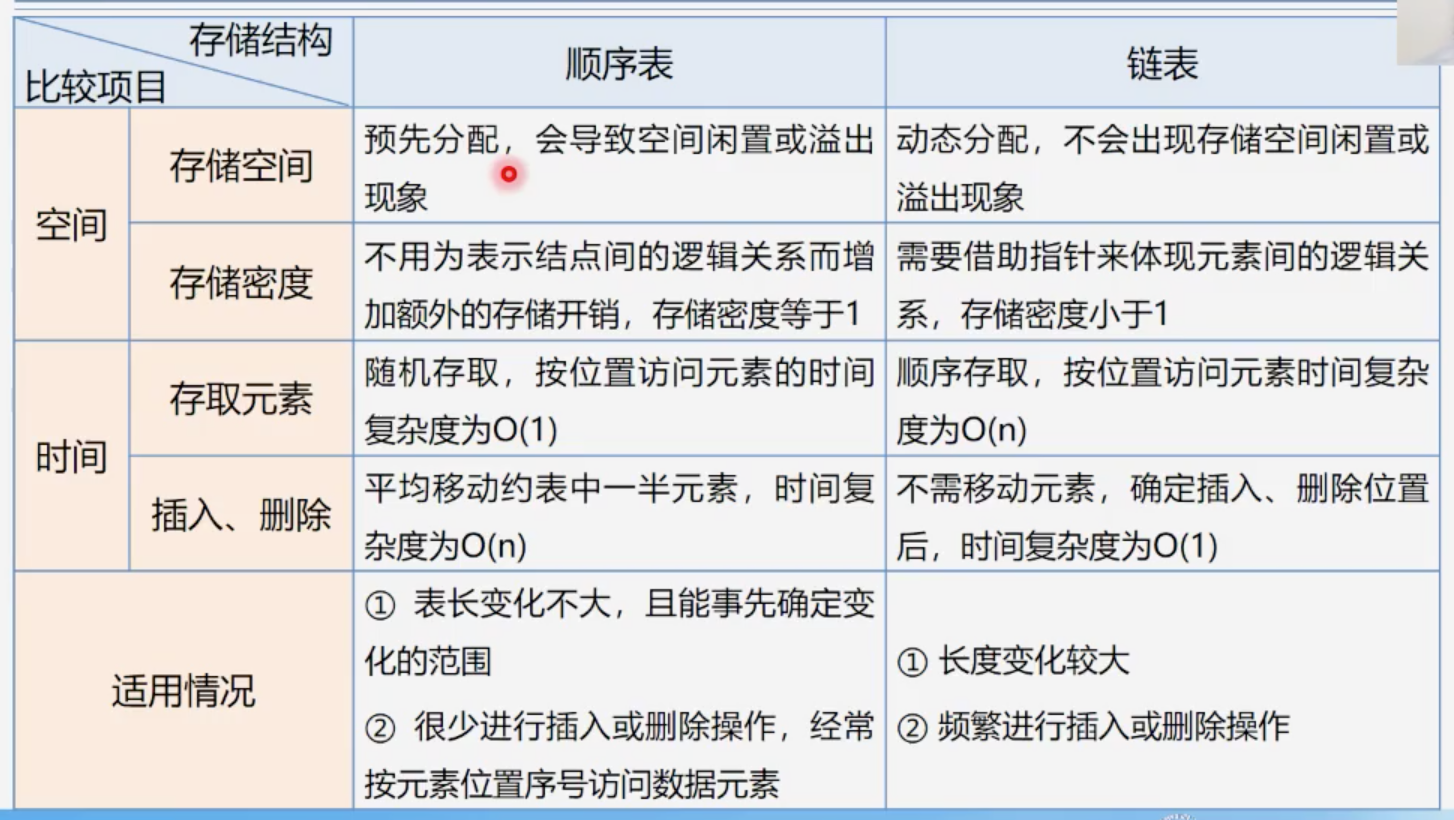
顺序表和链表的比较
- 链式存储
- 优点
- 节点空间可以动态申请和释放
- 数据元素的逻辑次序靠节点的指针来提示,插入和删除不需要移动数据元素
- 缺点
- 存储密度小,每个节点的指针域占用额外存储空间。数据域字节数小时,空间效率低
- 不能随机存取
线性表的应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
void union(List &a, &b){
a_len = ListLength(a);
b_len = ListLength(b);
for(int i = 1; i <= b_len; i++){
GetElem(b,i,e);
if(!LocateElem(a,e))
ListInsert(&a, ++a_len, e)
}
}
void MergeList_Sq(SqList a,SqList b,SqList &c){fin
pa = e.elem;
pb = b.elem;
c.length = a.length + b.length;
c.elem = new ElemType[c.length];
pc = c.elem;
pa_last = a.elem + a.length - 1;
pb_last = b.elem + b.length - 1;
while(pa <. pa_last && pb <= pb_last){
if(*pa <= *pb) *pc++ = *pa++;
else *pc++ = *pb++;
}
while(pa <= pa_last) *pc++ = *pa++;
while(pb <= pb_last) *pc++ = *pb++;
}
void Mergelist_L(LinkList &a,LinkList b,LinkList &c){
pa = a->next;pb = b->next;
pc = c = a;
while(pa && pb){
if(pa->data <= pb->data) {pc->next = pa; pc= pa; pa = pa->next;}
else{pc->next = pa; pc= pa; pa = pa->next;}
}
pc->next = pa ? pa : pb;
delete b;
}
void CreatePolyn(Polynomial &p,int n){
p = new PNode;
p->next = null;
for(int i = 1; i <= n; ++i){
s = new PNode;
cin >> s->ceof >> s->expn;
pre = p;
q = p->next;
while(q && q->expn < s->expn){
pre = q; q = q->next;
}
s->next = q;
pre->next = s;
}
}
|

2、栈(Stack)
限定插入和删除只能在表的“断点”进行的线性表
- 栈(Stack):后进先出(LIFO),只能在表尾进行插入和删除
- 栈顶/栈底:Top/Base
- 入栈/出栈:Push/Pop
1
2
3
4
5
6
7
8
9
10
| 栈底作用:
1. 表达式求值
设置两个栈:一个算符栈OPTR,用于寄存运算器;操作数栈OPND,寄存运算数和运算结果
从左往右扫描每一个字符:
if(运算数),将其压入栈OPND
else if 优先级:这个运算符 > OPTR栈顶运算符 入栈
else 从OPND弹出两个运算数,从OPTR弹出栈顶运算符进行运算,结果压入OPND
继续处理,知道遇到结束符为止
2. 舞伴问题
|
类型定义

常用操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
typedef struct {
SElemType *base;
SElemType *top;
int stackSize;
}SqStack
Status InitStack(SqStack &s){
s.base = new SElmType[maxsize];
if(!s.base) exit(overflow);
s.top = s.base;
s.stacksize = maxsiez;
return ok;
}
Status StackEmpty(SqStack s){
return s.top == s.base ? true : false;
}
Status ClearStack(SqStack s){
if(s.base) s.top = s.base;
return ok;
}
Status DestoryStack(SqStack s){
if(s.base){
delete s.base;
s.stacksize = 0;
s.base = s.top = null;
}
return ok;
}
Status Push(SqStack &s, SElemType e){
if(s.top - s.base == s.stacksize)
return ERROR;
else *s.top++ = e;
}
Status Pop(SqStack &s,SElemType &e){
if(s.base == s.top)
return ERROR;
else e = *--s.top;
return ok;
}
typedef struct StackNode{
SElemType data;
struct StackNode *next
}StackNode,*LinkStack;
LinkStack s;
void InitStack(Linkstack &s){
s = null;
return ok;
}
Status Push(LinkStack &s,SElemtype e){
p = new Stacknode;
p->data = e;
p->next = s;
s = p;
return ok;
}
Status Pop(LinkStack &s,SElemtype &e){
if(s == null) return ERROR;
e = s->data;
p = s;
s = s->next;
delete p;
return ok;
}
SElemType GetTop(LinkStack s){
if(s != null){
return s->data;
}
}
|
栈与递归
递归:若一个对象部分的包含它自己,或用它自己给自己定义,则称这个对象时递归的
- 1、递归定义的数学函数
- 阶乘函数
- 2、具有递归性质的数据结构
- 3、可递归求解的问题
- Eg:迷宫问题、汉诺塔
- 分治法:一个较为复杂的问题,能够分解为几个相对简单的且解法相似或相同的子问题来求解
必备条件:转换为新问题、简化、有边界
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
void p(参数表){
if(递归结束条件) 可直接求解步骤;
else p(较小参数);
}
long fact(long n){
if(n == 0) return 1;
else return n * fact(n - 1);
}
long fib(long n){
if(n == 1 || n == 2) return 1;
else return fib(n - 1) + fib(n - 2);
}
long fib(long n){
if(n == 1 || n == 2) return 1;
else{
long t1 = 1,t2 = 2;
for(long i = 3; i <= n; i++){
t3 = t1 + t2;
t1 = t2; t2 = t3;
return t3;
}
}
}
|
3、队列(Queue)
限定插入和删除只能在表的“断点”进行的线性表
- 栈(Stack):后进先出(LIFO),只能在表尾进行插入和删除
- 栈顶/栈底:Top/Base
- 入栈/出栈:Push/Pop
- 队列(Queue):先进先出(FIFO)
- 应用:脱机打印输出;多用户系统分时循环分配资源;网络报文传输
类型定义

常用操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| typedef struct {
QElemType *base;
int front;
int rear;
}SqQueue
Status Init(SqQueue &q){
q.base = new QElmtype[maxsize];
if(!q.base) exit(overflow);
q.front = q.rear = 0;
return ok;
}
int QueueLength(SqQueue q){
return (q.rear - q.front + maxsize) % maxsize
}
Status EnQueue(SqQueue &q,QElemType e){
if((q.rear + 1) % maxsize = q.front) return ERROR;
q.base[q.rear] = e;
q.rear = (q.rear + 1) % maxsize;
return ok;
}
Status DeQueue(SqQueue &q, QElemType &e){
if(q.front == q.rear) return ERROR;
e = q.base[q.front];
q.front = (q.front + 1) % maxsize;
return ok;
}
SElemType GetHead(SqQueue q)「
return q.front != q.rear ? q.base[q.front] : null;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
typedef struct Qnode{
QElmType data;
stuct Qnode *next;
}QNode,*QuenePtr
typedef struct{
QuenePtr front;
QuenePtr rear
}LinkQueue
Status InitQueue(LinkQueue &q){
q.front = q.rear=(QueuePtr)malloc(sizeof(QNode));
if(!q.front) exit(overflow)
q.front->next=null;
}
Status Destory(LinkQueue &p){
while(.front){
q.rear=->next;
free(q.front);
q.front=q.rear
}
return ok;
}
Status entry(LinkQueue &q,QElmType e){
p = (QueuePtr)malloc(sizeof(QNode));
if(!p) exit(overflow);
p->data = e;p->next = null;
q.rear->next = p;
return ok;
}
Status Dequeue(LinkQueue &q,QElemType &e){
if(q.front == q.rear) return error;
p = q.front->next;
e = p->data;
q.front->next = p.front;
if(q.rear==p) q.rear = q.front;
delete p;
return ok;
}
|
4、串
串(String):零个或多个任意字符组成的有限序列
子串:串中人一个字符组成的子序列(含空串 )
类型定义

存储结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#define MAXLEN 255
typedef struct{
char ch[MAXLEN + 1]
int length;
}
#define CHUNKSIZE 80
typedef struct Chunk{
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk
typedef struct {
Chunk *head,*tail;
int curlen;
}LString
|
运算
模式匹配算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
int Index_BF(String s,String t,int pos){
int i=pos,j=1,index=0;
while(i <= s.length && j <= t.length){
if(s.ch[i] == t.ch[j]) {++i;++j;}
else {i=i-j+2;j=1;}
}
if(j >= t,length) index = i-t.length;
else return index;
}
int KMP(char * t, char * p)
{
int i = 0;
int j = 0;
while (i < strlen(t) && j < strlen(p))
{
if (j == -1 || t[i] == p[j])
{
i++;j++;
}
else j = next[j];
}
if (j == strlen(p))
return i - j;
else
return -1;
}
void getNext(char * p, int * next)
{
next[0] = -1;
int i = 0, j = -1;
while (i < strlen(p))
{
if (j == -1 || p[i] == p[j])
{
++i;
++j;
next[i] = j;
}
else
j = next[j];
}
}
|
2、非线性结构
1、数组
按一定格式排列起来具有相同类型的数据元素的集合
- 二维数组
- 非线性结构:每个数据即在行表又在列表
- 线性结构定长线性表:线性表每个数据也是定长线性表
N 维数组

矩阵压缩

从上到下,从左到右存储

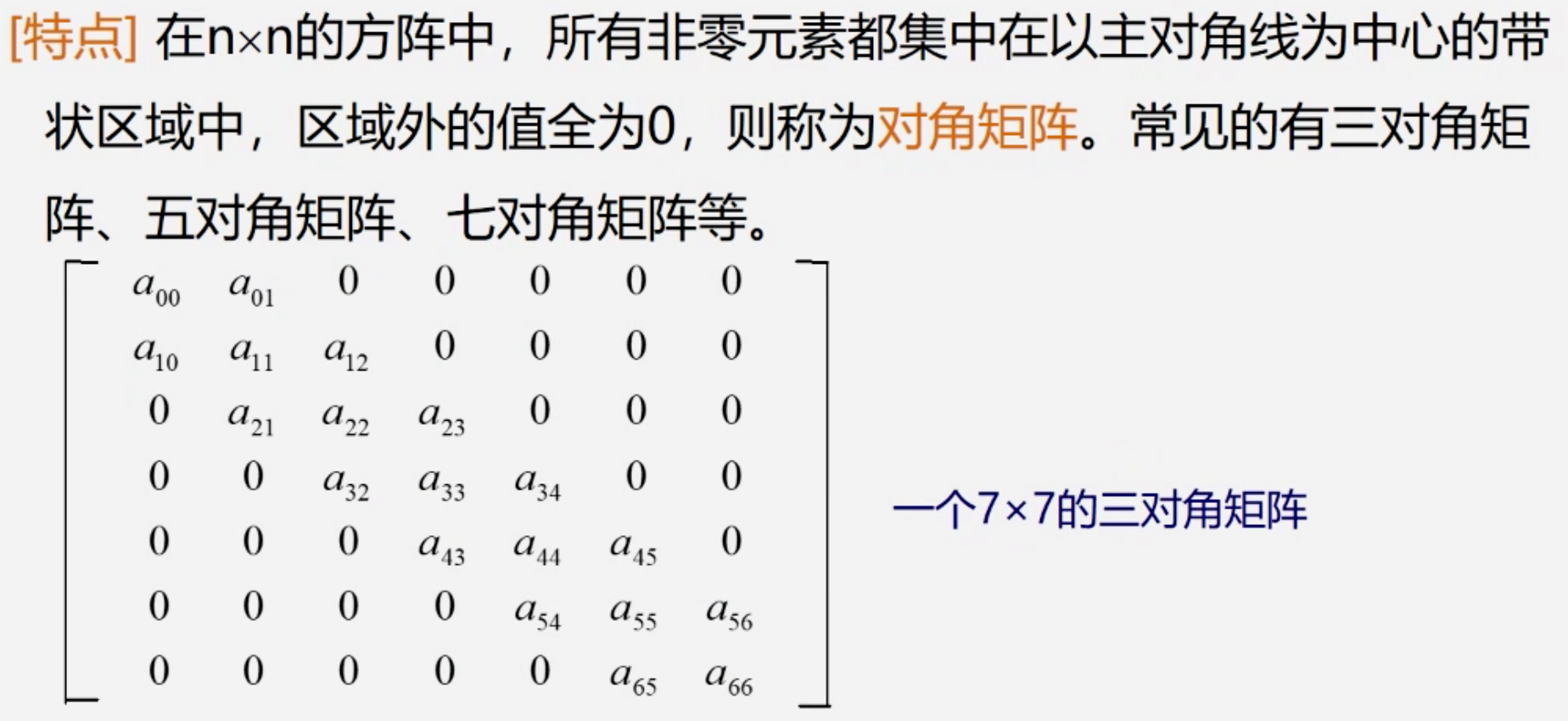
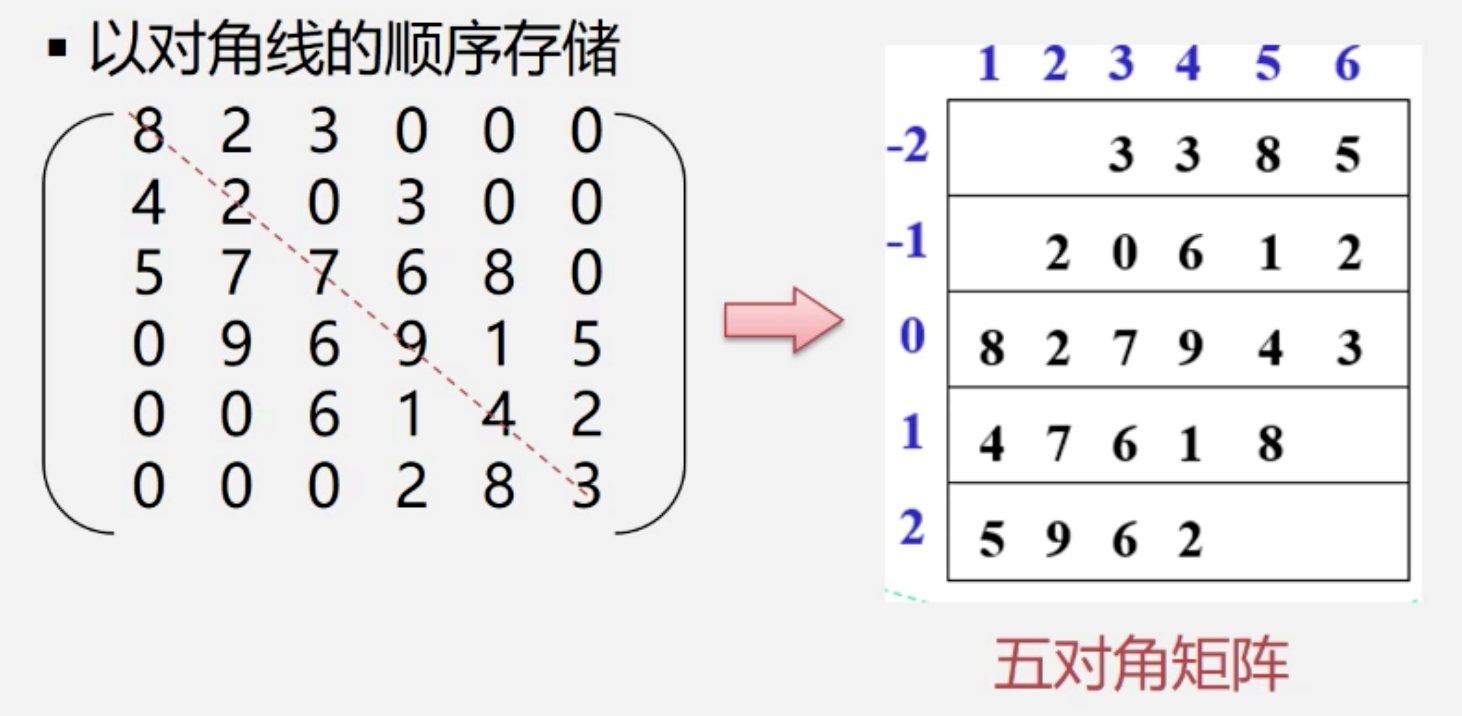
斜着按对角线存储,先存主对角线,再存其他的

三元组法:
使用三元组存储;{(i, j, a),…}分别为横/纵坐标,值
优点:灵活插入和删除
十字链表法:
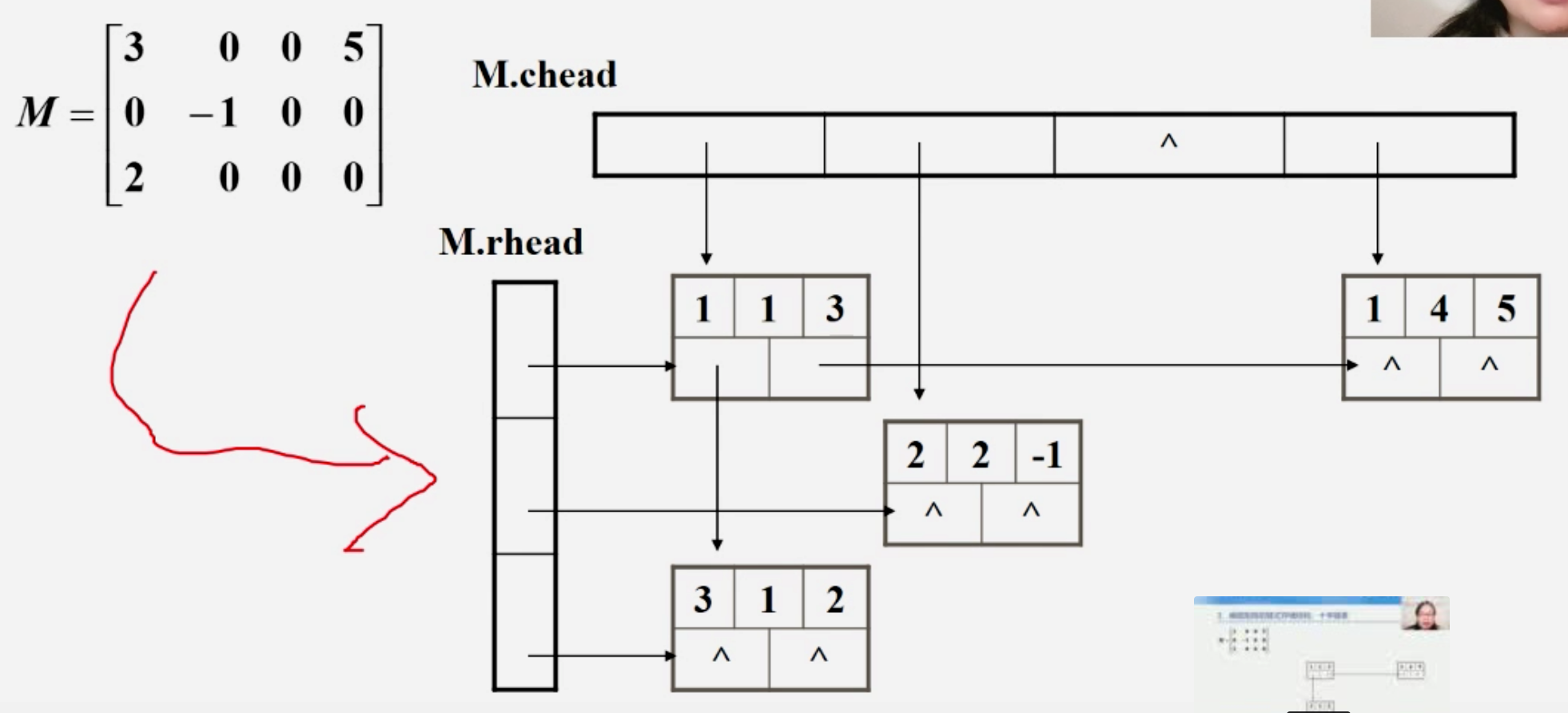
2、广义表
定义

性质


对比

基本运算

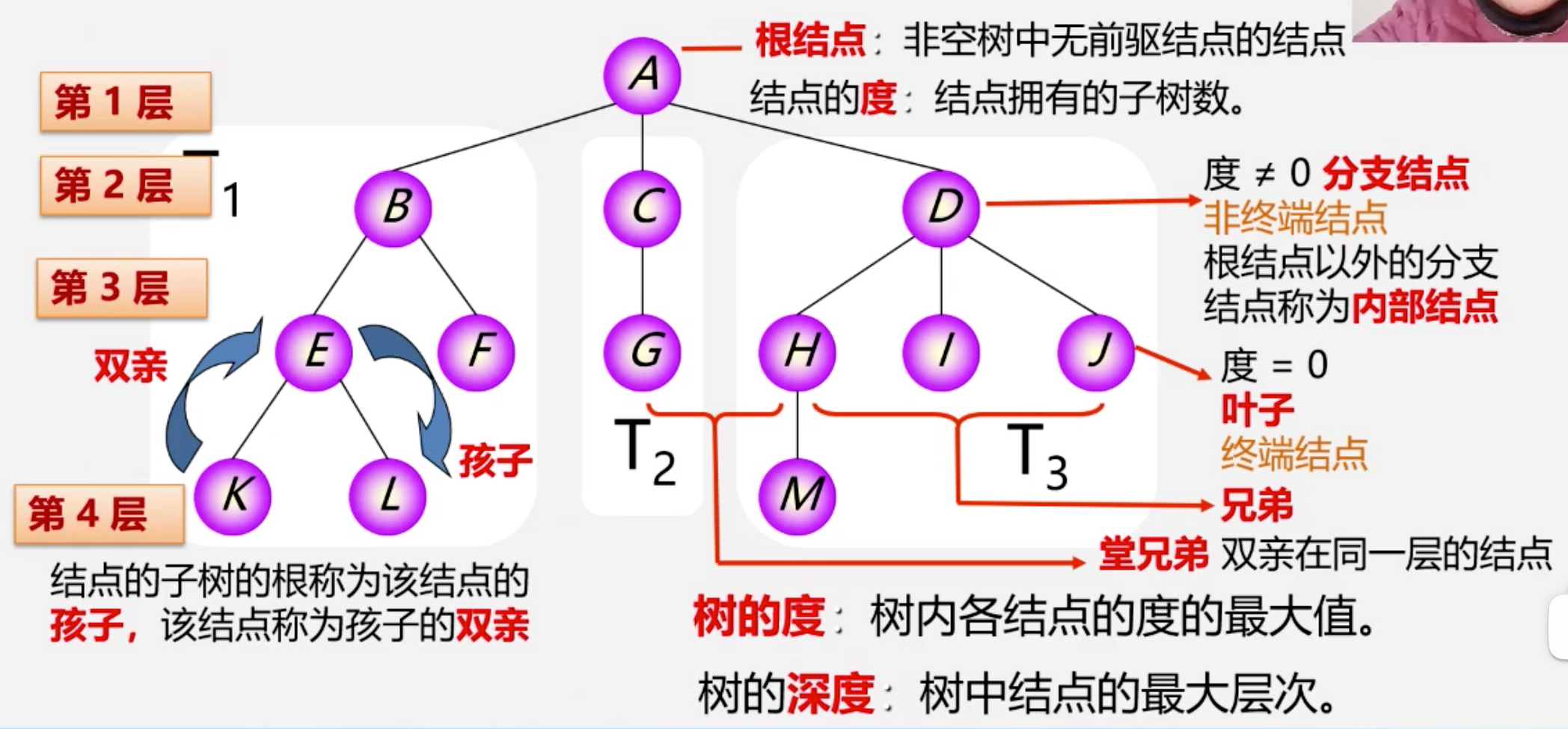
3、树
定义

4、二叉树
性质特殊,单独从 🌲 中拿出来讲

定义


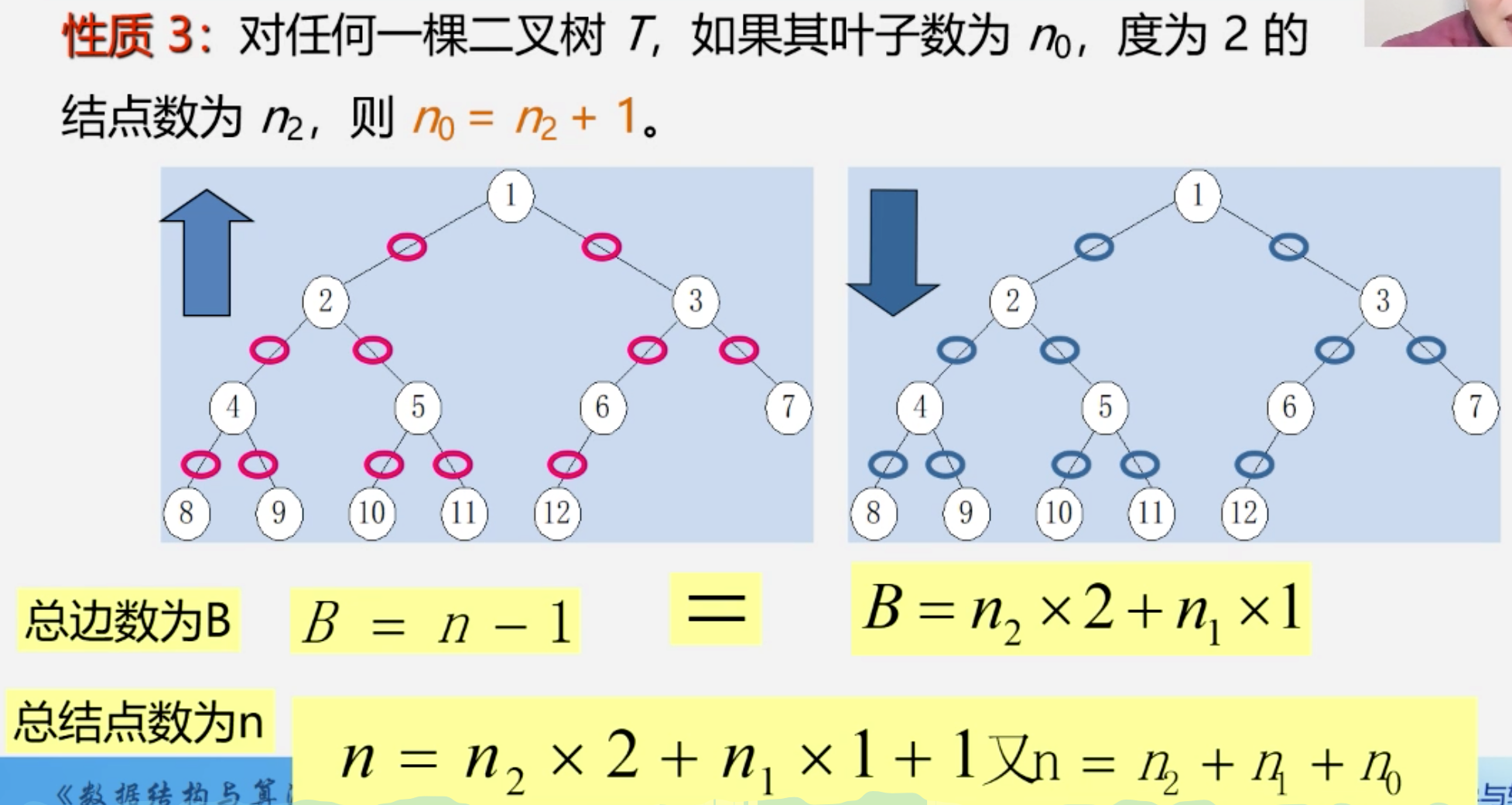
性质

第 i 层至少有 1 个节点

深度为 k 时至少有 k 个节点


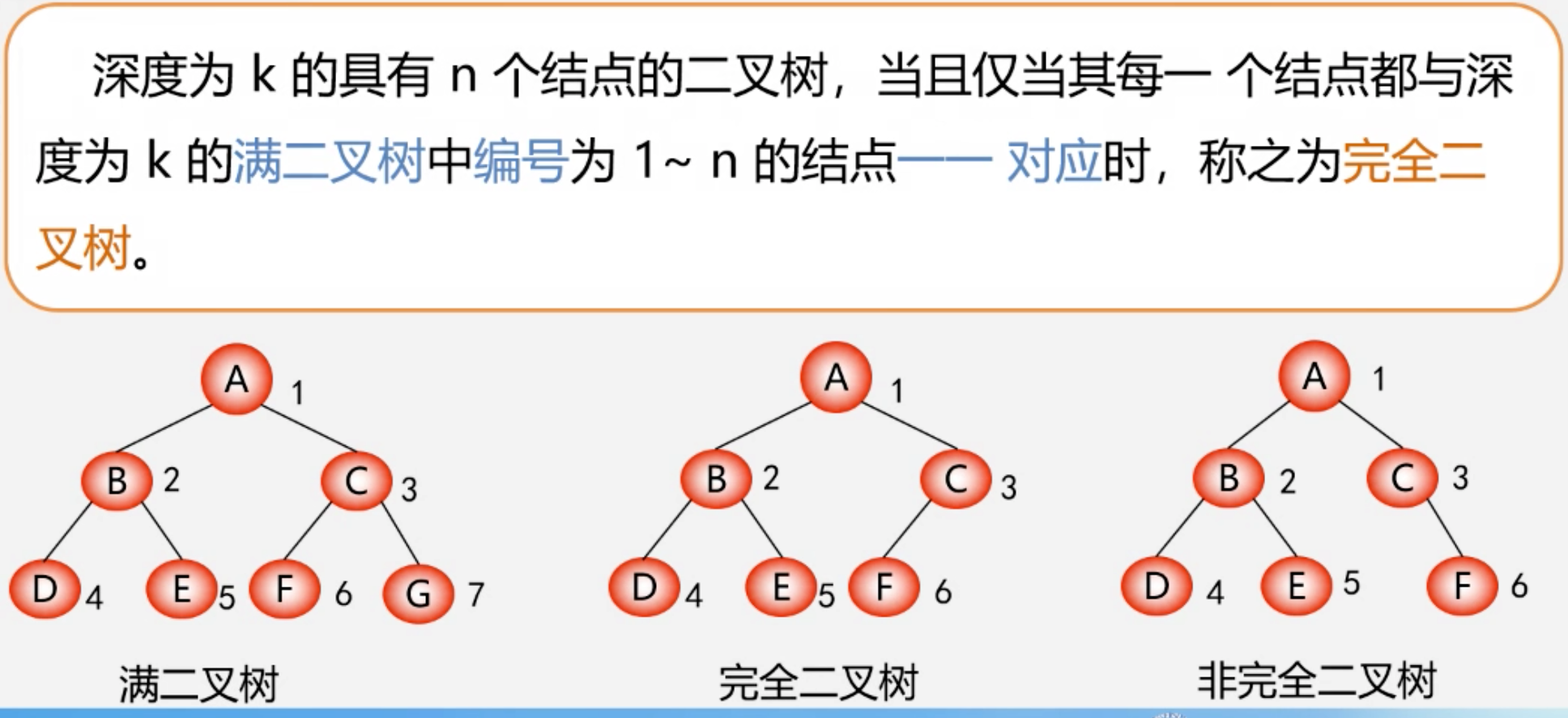
特殊形式
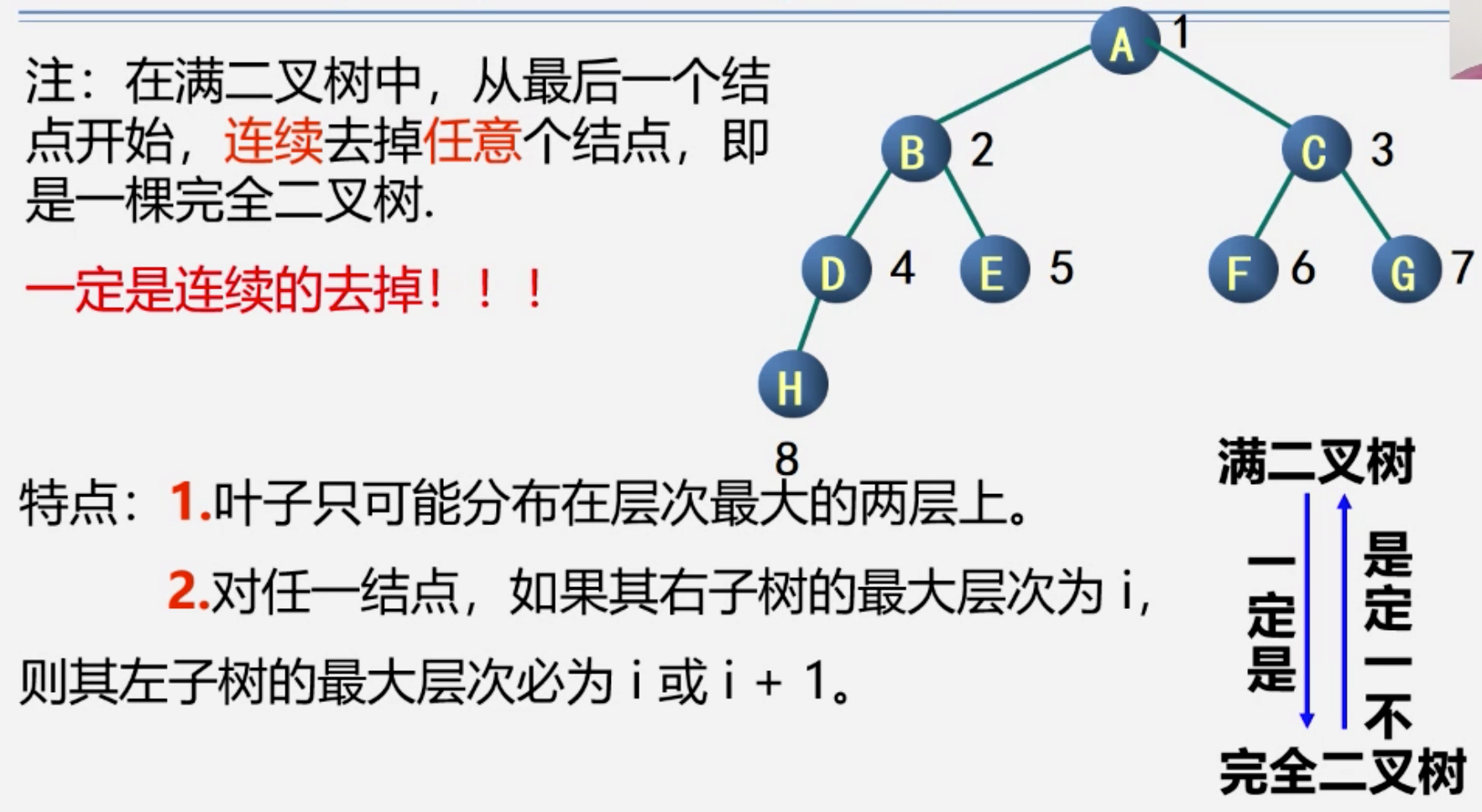
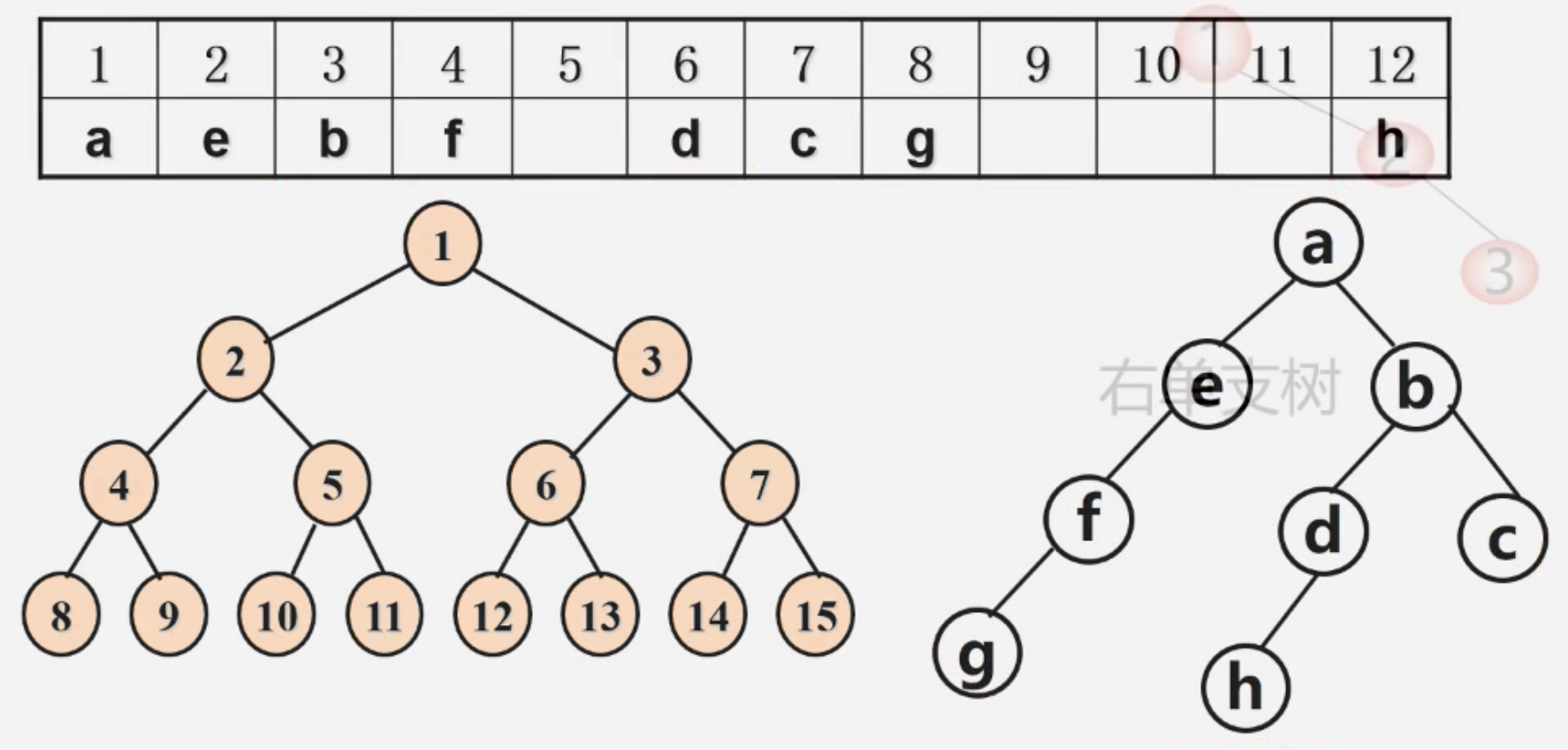
存储
从上到下,从左到右存储,空的不写
缺点:最坏情况,单支 🌲 浪费巨大空间
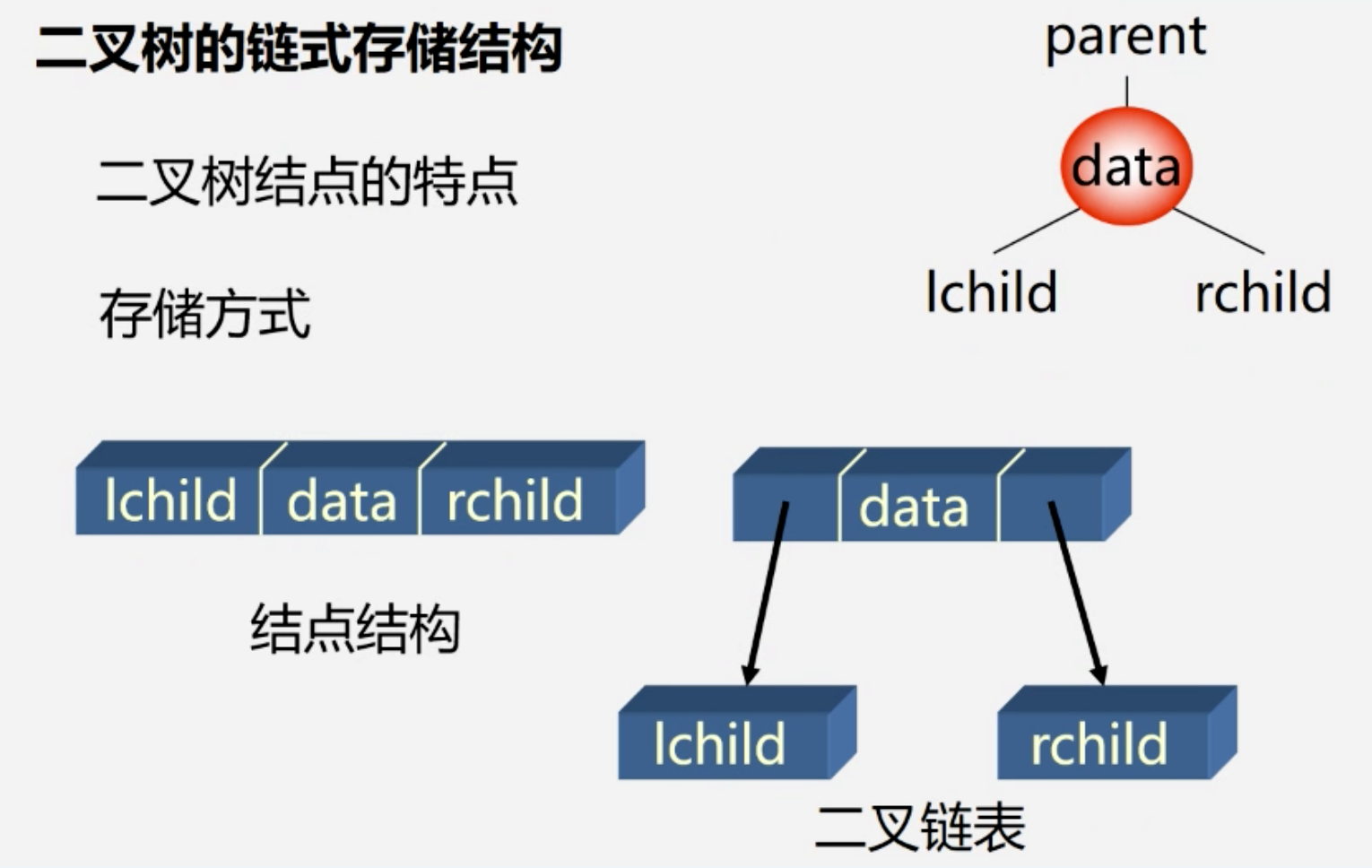
存储结构

实现
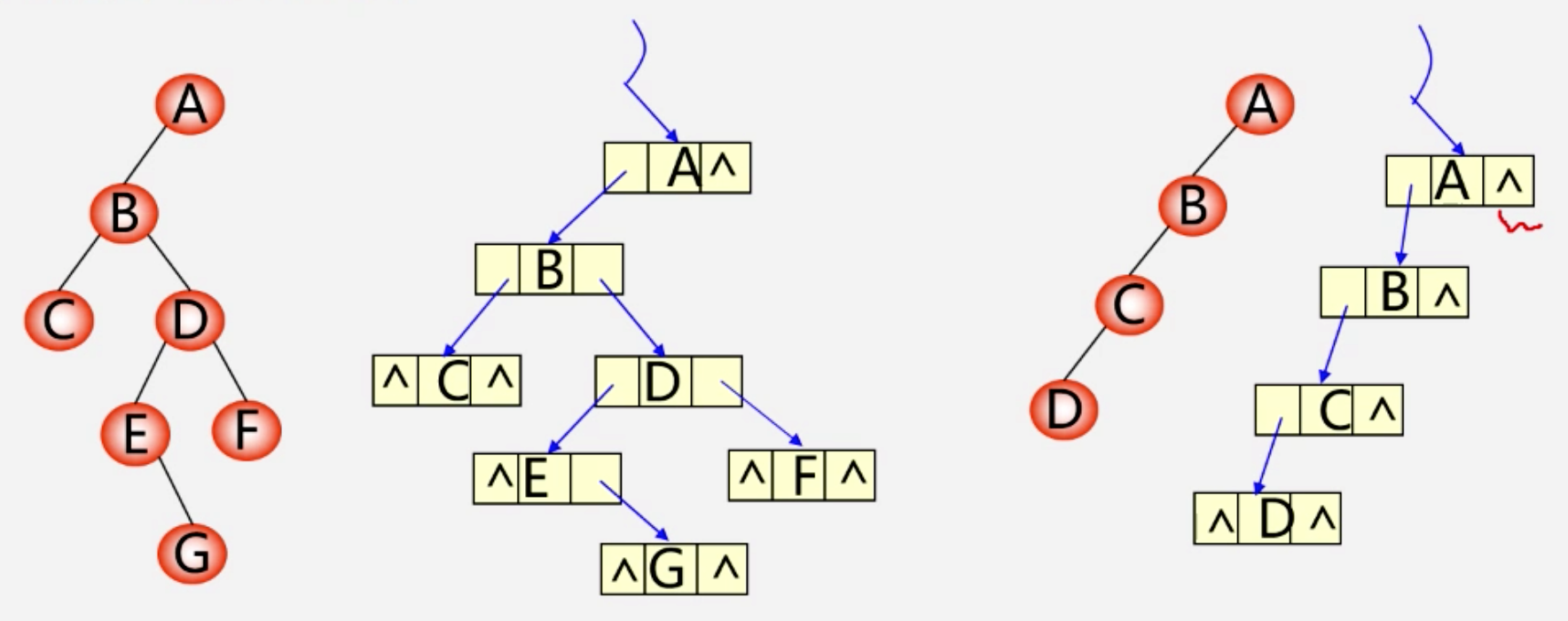
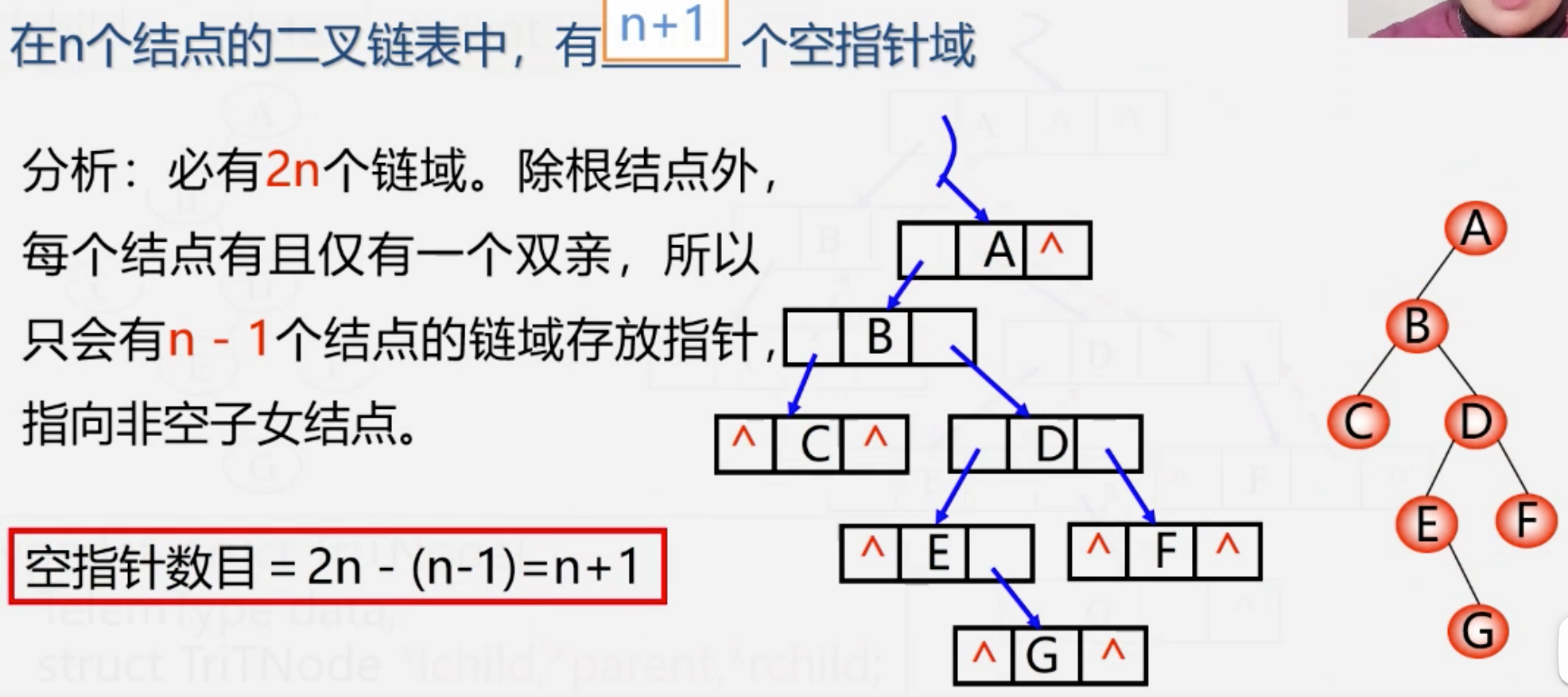
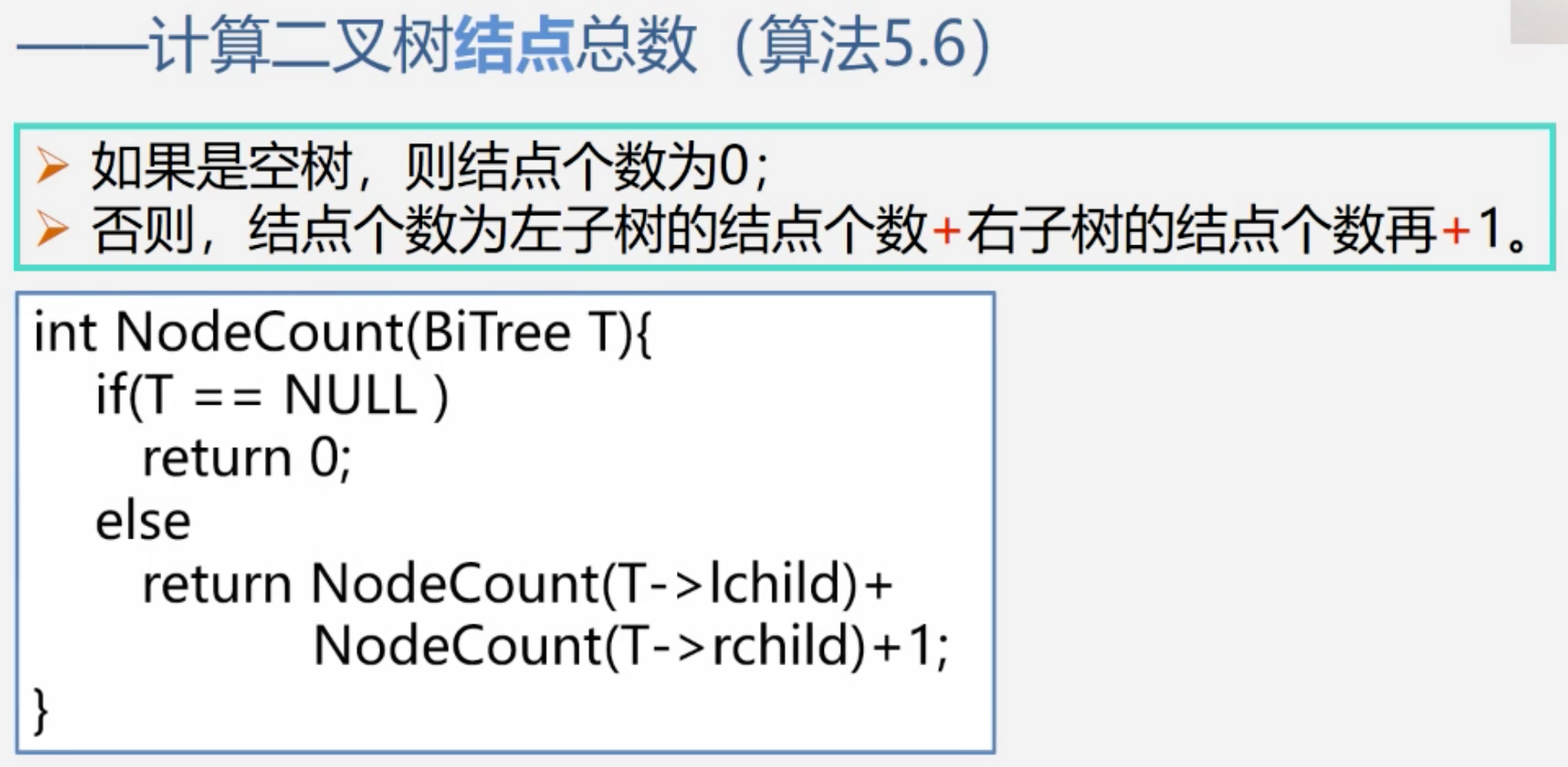
遍历

先中 or 中后可确定唯一二叉树,先后不能确定唯一二叉树







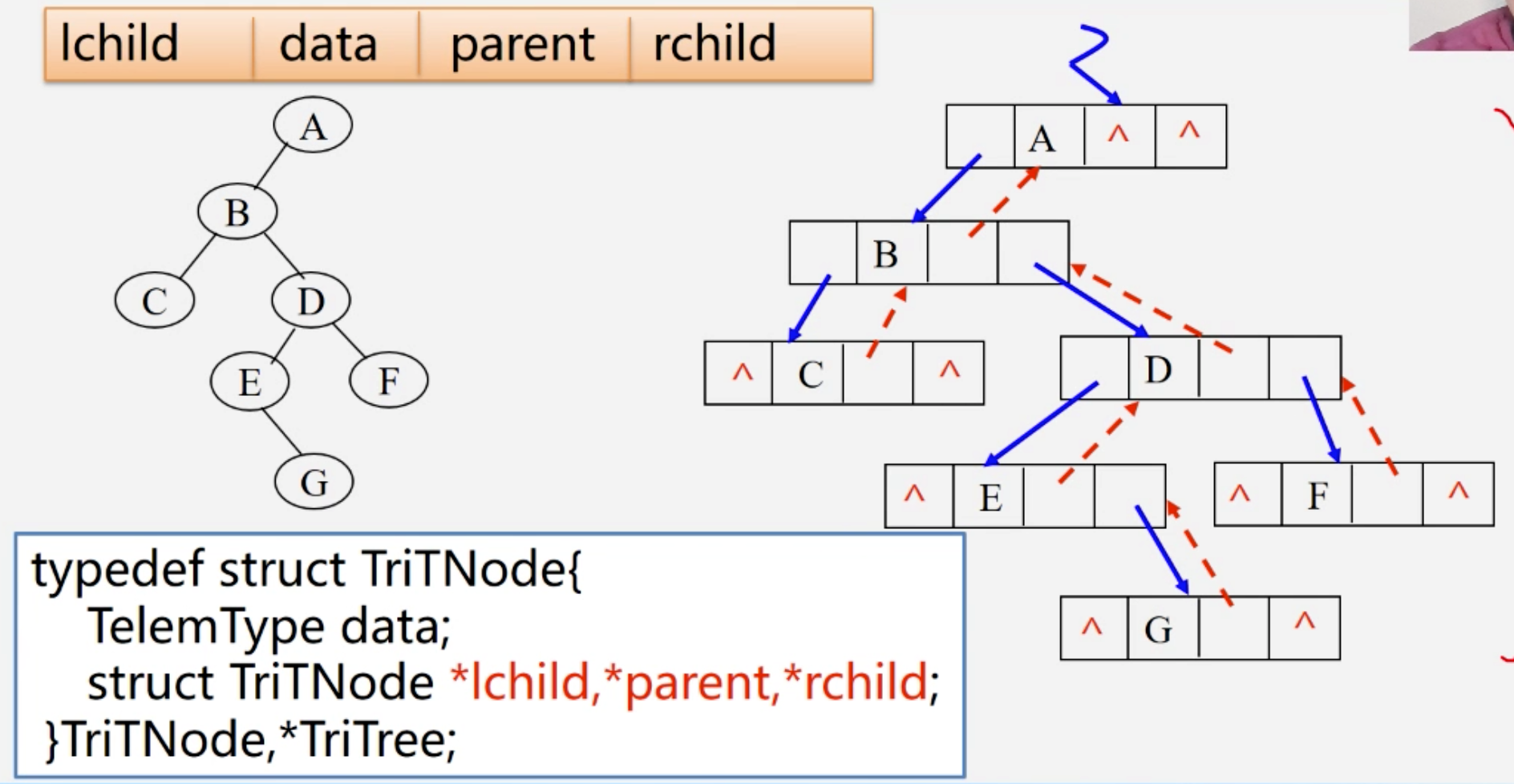
线索二叉树

森林
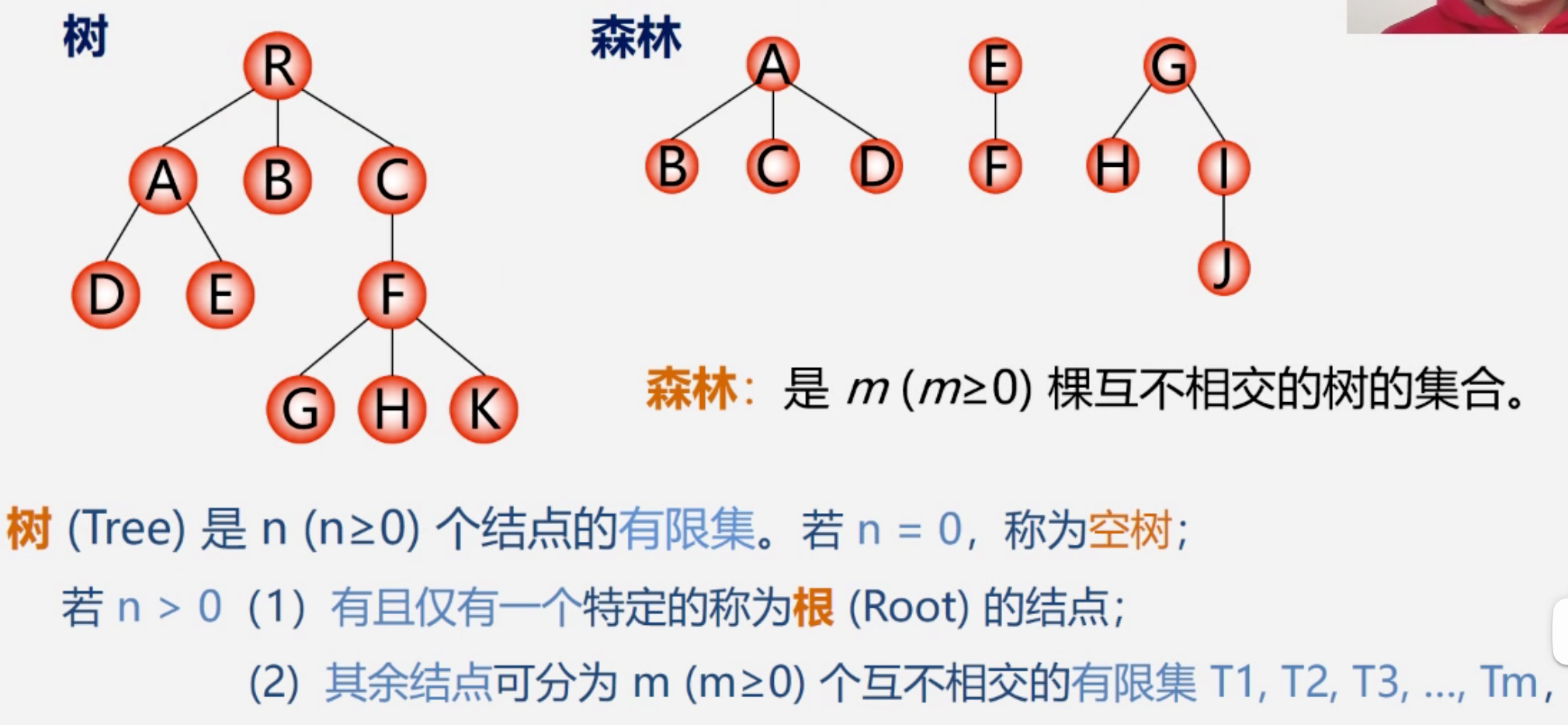
6、图
三、基本数据处理技术
1、查找技术
2、排序技术
