狂神Redis教程
最具有代表性的 KV 数据库,常用于分布式缓存
一、NoSQL 概述
1、为什么要使用 NoSQL
1、单机 MySQL
- 瓶颈:
- 数据量太大,一个机器放不下
- 数据索引,机器内存不够
- 访问量(混合读写),一个机器承受不了
2、MemCached + MySQL+ 垂直拆分(读写分离)
- 网站大部分都是读操作,每次都查询数据库就很麻烦,使用缓存保持效率
- 发展过程:优化数据结构和索引 –> 文件缓存(IO) –> Memcached(当时最流行)
3、分库分表 + 水平拆分(MySQL 集群)
- 技术和业务发展的同时,对人的要求越来越高
本质:数据库(读&写)
- MylSAM:表锁,十分影响效率,高并发下出现严重问题
- InnoDB:行锁
- 慢慢的用分库分表减轻写的压力,但 mySQL 推出的表分区没有被大规模使用
4、为什么要 NoSQL
- 用户个人信息,社交网络,地理位置,用户日志
- 数据多种多样:定位,音乐,热榜,图片
- NoSQL 可以很好的处理以上情况:
不需要固定格式去存储这些,不需要太多操作去横向扩展
2、什么是 NoSQL
NoSQL = Not Only SQL,泛指非关系型数据库
非关系型数据库:
NoSQL 特点:
解耦
- 方便扩展,数据之间没有关系,很好扩展
- 大数据量高性能(redis 一秒写 8w 次,读 11w 次,NoSQL 的缓存记录级,是一种细粒度的缓存,性能比较高)
- 数据类型多样,不需要实现设计数据库,随取随用
- 传统 RDBMS 和 NoSQL 区别
1 | |
了解:3V + 3 高
3V:海量 Volume,多样 Variety,实时 Velocity
3 高:高并发,高可扩,高性能
真正在公司中的实践:NoSQL 与 RDBMS 结合使用最强大
3、阿里巴巴演进分析
敏捷开发,极限编程
1 | |
- 大型互联网公司应用问题
- 数据问题太多
- 数据源繁多,经常重构
- 数据改造,大面积改造
- 解决方案:统一的数据服务层 UDSL
4、NoSQL 四大分类
1、KV 键值对
2、文档类型数据库
- MongoDB
- 一个基于分布式文件存储的数据库,C++编写,用来处理大量的文档
- 介于关系型和非关系型数据库之间,非关系型数据库功能最丰富,最像关系型数据库的
3、列存储数据库
- HBase
- 分布式文件系统
4、图关系数据库
二、Redis 入门
Redis 是什么?
Redis (Remote Dictionary Server),远程字典服务
Redis 是一个开源(BSD 许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA 脚本(Lua scripting), LRU 驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis 哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
Redis 能做什么?
- 内存存储,持久化,内存断电即失,持久化很重要(rdb,aof)
- 效率高,可用于高速缓存
- 发布订阅系统
- 地图信息分布
- 计时器,计数器
Redis 特性
- 多样的数据类型
- 持久化
- 集群
- 事务
Redis 安装步骤
1、基本使用
1 | |
- 压力测试参数
2、基础知识
- 默认有 16 个数据库,默认使用第 0 个数据库
1 | |
常见 Bug 及解决
1、MISCONF Redis is configured to save RDB snapshots, but it is currently not a
- config stop-writes-on-bgsave-error no (临时解决)
- 最好的办法
三、五大数据类型
1、Redis-Key
1 | |
2、String
1 | |
3、List
- 所有的 list 命令以 l 开头
1 | |
实际为一个链表,每个 node 的 right/left 都要可以插入值
在左右两边插入或改动值效率最高,中间元素效率较低
4、Set
set 中的值不能重复
1 | |
5、Hash
Hash == KEY– <key,value>
1 | |
6、Zset
1 | |
四、三种特殊数据类型
1、Geospatial 地理位置
可以实现两地位置信息,两地之间的距离
geoadd
- 添加地理坐标值
- 规则
1 | |
- 例子
1 | |
geopos
- 获得当前位置坐标
1 | |
geodist
两地之间的距离
- 如果两个位置之间的其中一个不存在, 那么命令返回空值
GEODIST命令在计算距离时会假设地球为完美的球形, 在极限情况下, 这一假设最大会造成 0.5% 的误差。- 单位
- m:米(默认值)
- km:千米
- mi:英里
- ft:英尺
1 | |
georadius
以给定的经纬度为中心, 找出某一半径内的元素
1 | |
几个可选参数
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。WITHCOORD: 将位置元素的经度和维度也一并返回。WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
1 | |
排序
ASC: 根据中心的位置, 按照从近到远的方式返回位置元素。DESC: 根据中心的位置, 按照从远到近的方式返回位置元素。
1 | |
截取
COUNT:根据参数 n 返回 n 个数据- 在默认情况下, GEORADIUS 命令会返回所有匹配的位置元素。 虽然用户可以使用**COUNT **
**<count>**选项去获取前 N 个匹配元素, 但是因为命令在内部可能会需要对所有被匹配的元素进行处理, 所以在对一个非常大的区域进行搜索时, 即使只使用COUNT选项去获取少量元素, 命令的执行速度也可能会非常慢。 但是从另一方面来说, 使用COUNT选项去减少需要返回的元素数量, 对于减少带宽来说仍然是非常有用的。
返回值
- 在没有给定任何
WITH选项的情况下, 命令只会返回一个像 [“New York”,”Milan”,”Paris”] 这样的线性(linear)列表。 - 在指定了
WITHCOORD、WITHDIST、WITHHASH等选项的情况下, 命令返回一个二层嵌套数组, 内层的每个子数组就表示一个元素。
在返回嵌套数组时, 子数组的第一个元素总是位置元素的名字。 至于额外的信息, 则会作为子数组的后续元素, 按照以下顺序被返回:
- 以浮点数格式返回的中心与位置元素之间的距离, 单位与用户指定范围时的单位一致。
- geohash 整数。
- 由两个元素组成的坐标,分别为经度和纬度。
2、HyperLogLog
- 基数统计,有误差,可忽略
- 非常节省内存,2^64 个数据也只需要 12KB 内存
- 适合统计各种计数,比如
注册 IP 数、每日访问 IP 数、页面实时UV、在线用户数等- 只能统计数量,而没办法去知道具体的内容是什么
pfadd
- 新建元素
1 | |
pfcount
- 统计数量
1 | |
pfmerge
- 合并
- 合并后的数据
1 | |
3、Bitmaps
位图:适合只有两个状态的需求
- 0 和 1 相对:活跃/不活跃,登陆/未登陆,打卡/未打卡
setbit
- 用 Bitmaps 记录一周的打卡
1 | |
getbit
- 获取某一天的状态
1 | |
bitcout
- 统计结果
1 | |
事务
Redis 事务本质:一组命令的集合。一个事务中所有命令都会被序列化,执行过程中按照顺序执行
事务概念
- Redis 没有隔离级别的概念
- Redis 单条命令保证原子性,事务不保证原子性
- Redis 事务过程
- 开启事务:multi
- 命令入队:……
- 事务中所有事务没用被直接执行,发起执行命令时才会执行
- 执行事务:exec
1 | |
异常
编译期异常
- 代码有问题,事务中所有命令都不执行
1 | |
运行时异常
- 类似 1/0,如果语法没问题,其他命令可以执行
1 | |
监控
- 悲观锁:认为做什么都会出问题,做什么都加锁
- 乐观锁:认为什么时候都不出问题,加一个 version!更新数据的时候判断一下
测试多线程监控
- 1、先单独执行左边事务,成功
- 2、中间线程,先开始监视,不执行事务
- 3、获取 money 并设置值,此时 exec 中间线程的事务,失败
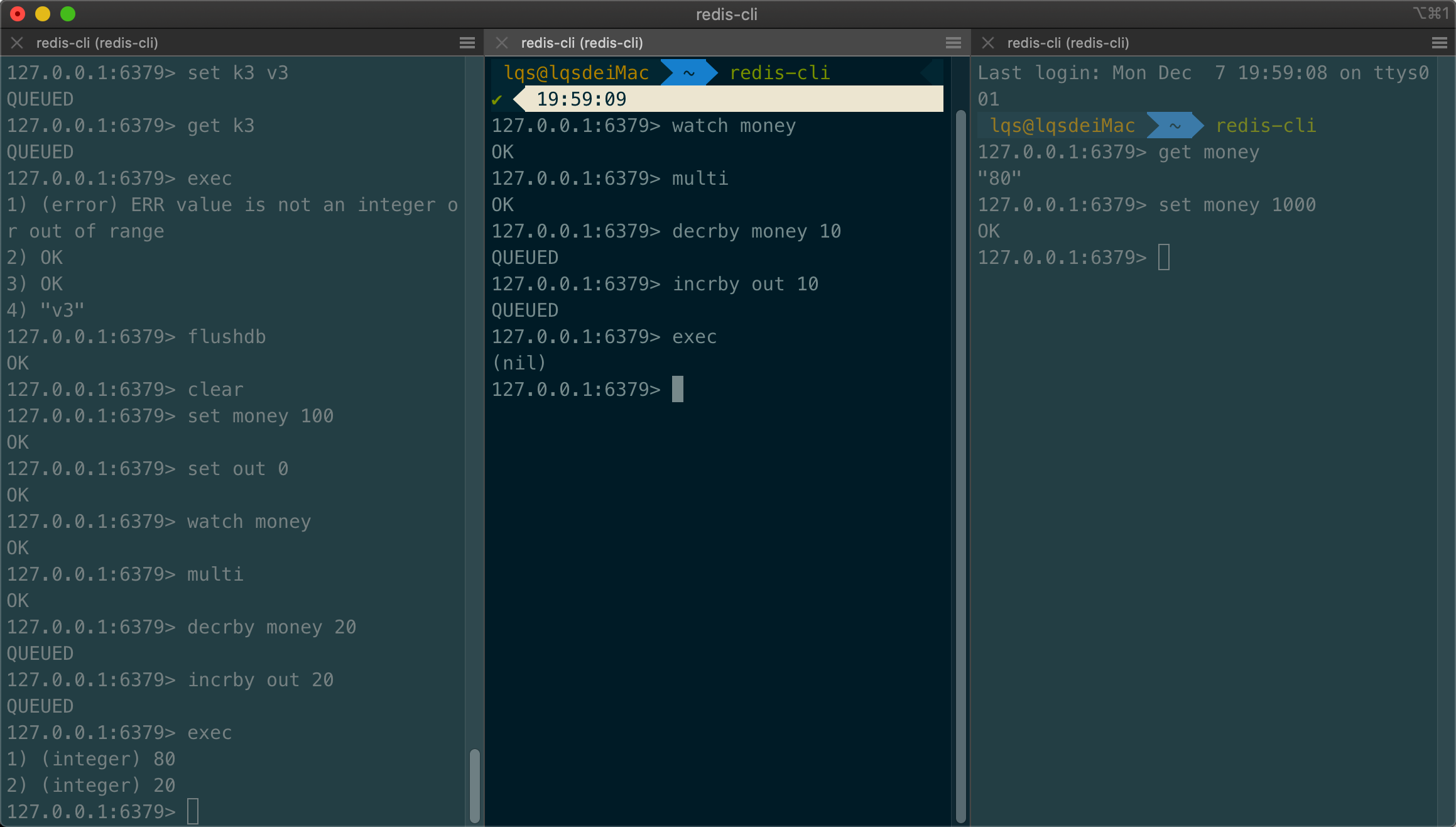
- 测试多线程修改值,使用 watch 可以当作 Redis 的乐观锁操作
Jedis
Redis 官方推荐的的 Java 连接开发工具,使用 Java 操作 Redis 中间件
SpringBoot 整合 Redis
SpringData 是和 SpringBoot 齐名的项目
在 SpringBoot2.x 之后,SpringData 使用 Lettuce 替代率 Jedis
Jedis:直连技术,多线程操作不安全;想要避免不安全可以使用 pool 技术,更像 BIO
Lettuce:采用 netty,实例可以在多个线程在进行共享,多线程安全,更像 NIO
1、源码分析
1 | |
2、自定义 redisTemplate
1 | |
3、自定义 Redis 工具类
1 | |
Redis.conf 详解
- 通过配置文件启动
- Mac 使用 HomeBrew 安装的 Redis 配置文件位置为:/usr/local/etc/redis.conf
- 配置文件对大小写不敏感
1、网络
1 | |
2、通用
1 | |
3、快照
- 持久化,在规定的时间内,执行了多少操作,会持久化到.rdb.aof 文件中
1 | |
4、主从复制
5、安全
- 默认没用密码
1 | |
- 可以加一个密码
- 设置完之后重启 redis
1 | |
6、客户端
1 | |
7、APPEND ONLY 模式
1 | |
Redis 持久化
Redis 是内存数据库,关机数据丢失,所以需要持久化操作
1、RDB
Redis DataBase
默认的持久化规则
在指定时间间隔内将内存中的数据集快照写入磁盘,即 SnapShot 快照,恢复时将快照文件存进内存
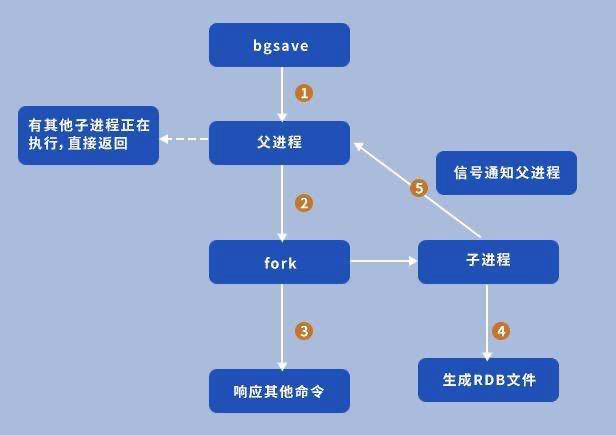
介绍
- 会单独创建一个子进程进行持久化,先将数据写入到一个临时文件中。
- 待持久化结束之后,在用临时文件替换上次持久化的文件
- 整个过程中,主进程不进行任何 IO 操作,确保极高性能
优点:性能比 AOF 更高效,需要大规模数据且数据恢复完整性不太敏感可以使用 RDB
缺点:最后一次持久化的数据可能丢失
触发规则
save 规则满足的情况
执行 flushall 命令
退出 Redis
恢复文件
文件名:dump.rdb
将 rdb 文件放入 redis 启动目录即可
1 | |
2、AOF
Append Only File
以日志的形式记录每个写操作,将 Redis 执行过的所有指令记录下来
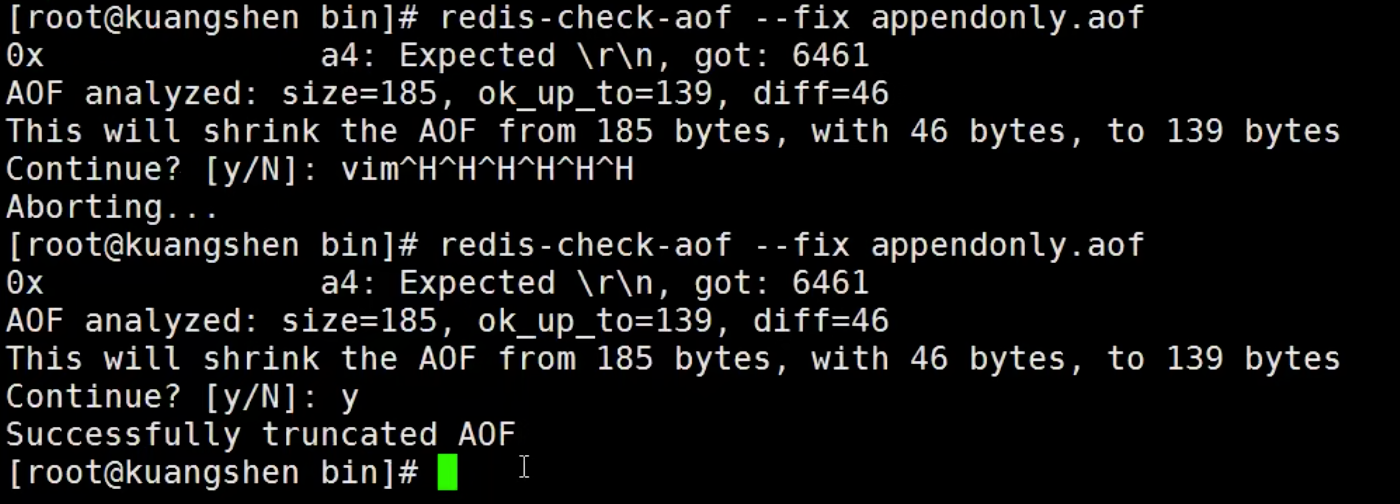
- 只许追加文件但不可以改写文件,Redis 启动之后会读取该文件重新构建数据
- 如果 aof 文件有错误,Redis 会启动失败,利用自动提供的工具
redis-check-aof进行修复
- 优点
- 每次修改都同步,文件完整性更好
- 每次同步一次,可能会丢失一秒的数据
- 从不同步,效率最高
- 缺点
- 相对于数据文件来说,aof 远大于 rdb,修复文件慢
- aof 运行效率要比 rdb 慢,默认使用 rdb
扩展
- 只做缓存,就不需要持久化
- 同时开启两种持久化
- Redis 重启的时候首先载入 AOF 文件恢复原始数据,通常情况下 AOF 比 RDB 数据更完整
- RDB 数据不实时,同时使用两者也只会找 AOF 文件。建议不使用 AOF,只用 RDB 备份数据库,方便快速重启,不会有 AOF 潜在的 bug
- 性能建议
- RDB 文件只用作后背用途,建议只在 Slave 上持久化 RDB 文件,15 分钟备份一次即可,即 save 900 1
- 使用 AOF 的好处:情况最恶劣也只丢失不超过 2s 的数据,编写脚本 load AOF 文件即可。代价:带来持续 IO。AOF rewrite 过程中产生的新数据到文件的阻塞基本不可避免;磁盘许可时,应该尽量见效 AOF rewrite 的频率,将默认值从 64M 改到 5G 以上
- 不使用 AOF,仅靠 Master-Slave Replcation 也可实现高可用,节省 IO,减少 rewrite 带来的系统波动。代价:如果 master/Slave 通水倒掉,会丢失十几分钟的数据,启动脚本也要比较 master/Slave 的 RDB 文件,载入较新的
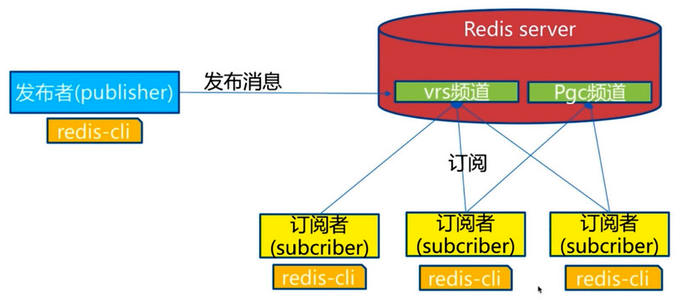
Redis 发布订阅
Redis 发布订阅(pub/sub):一种消息通信模式,发送者发送信息,订阅者接收消息。微信/微博关注系统
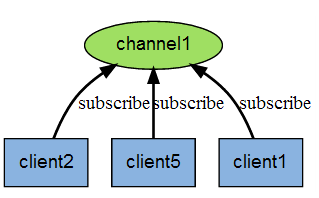
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
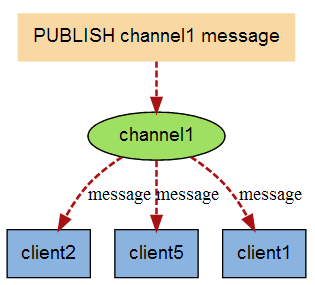
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
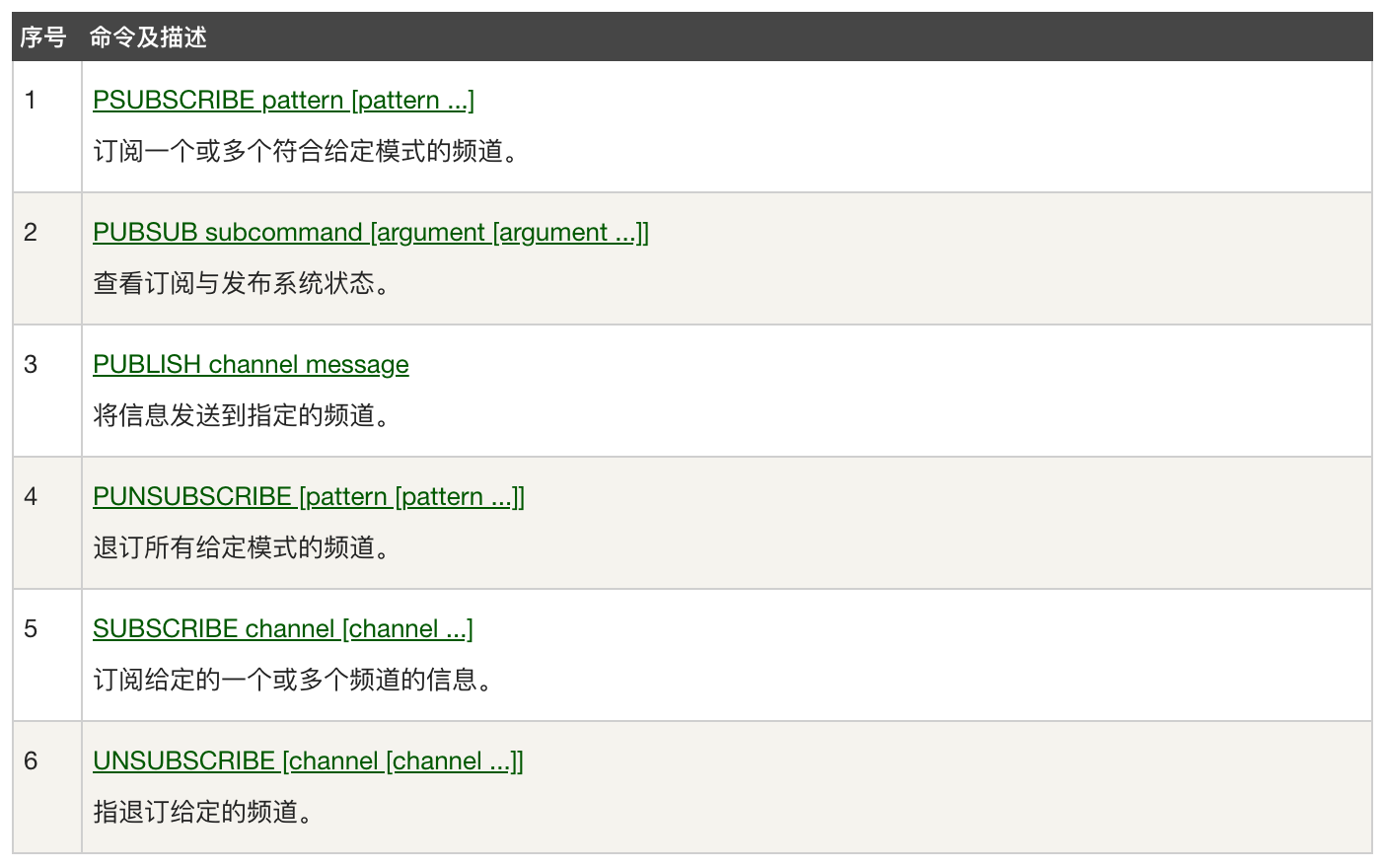
命令
- 基本命令
- 两个订阅者都订阅一个发布者
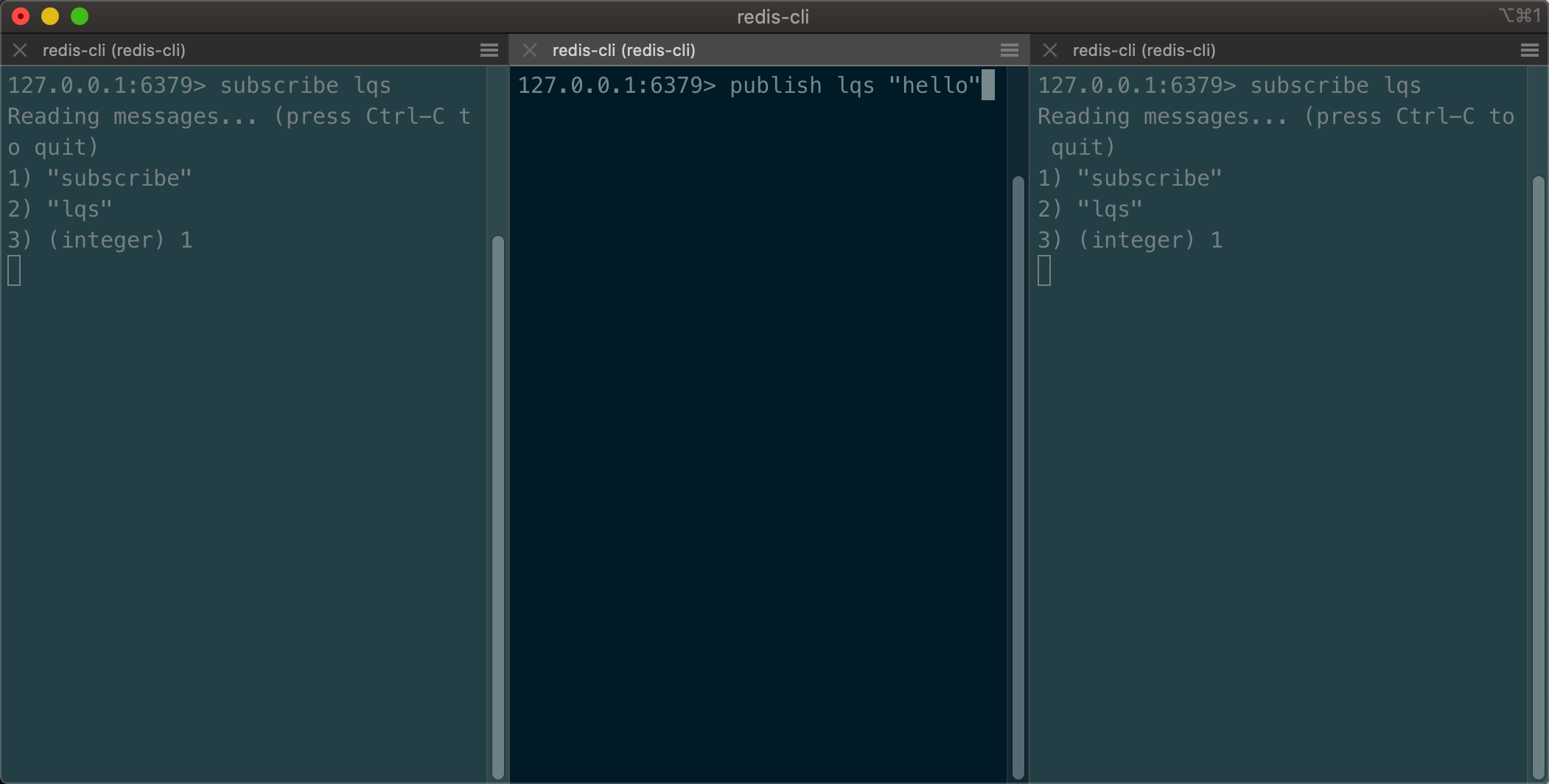
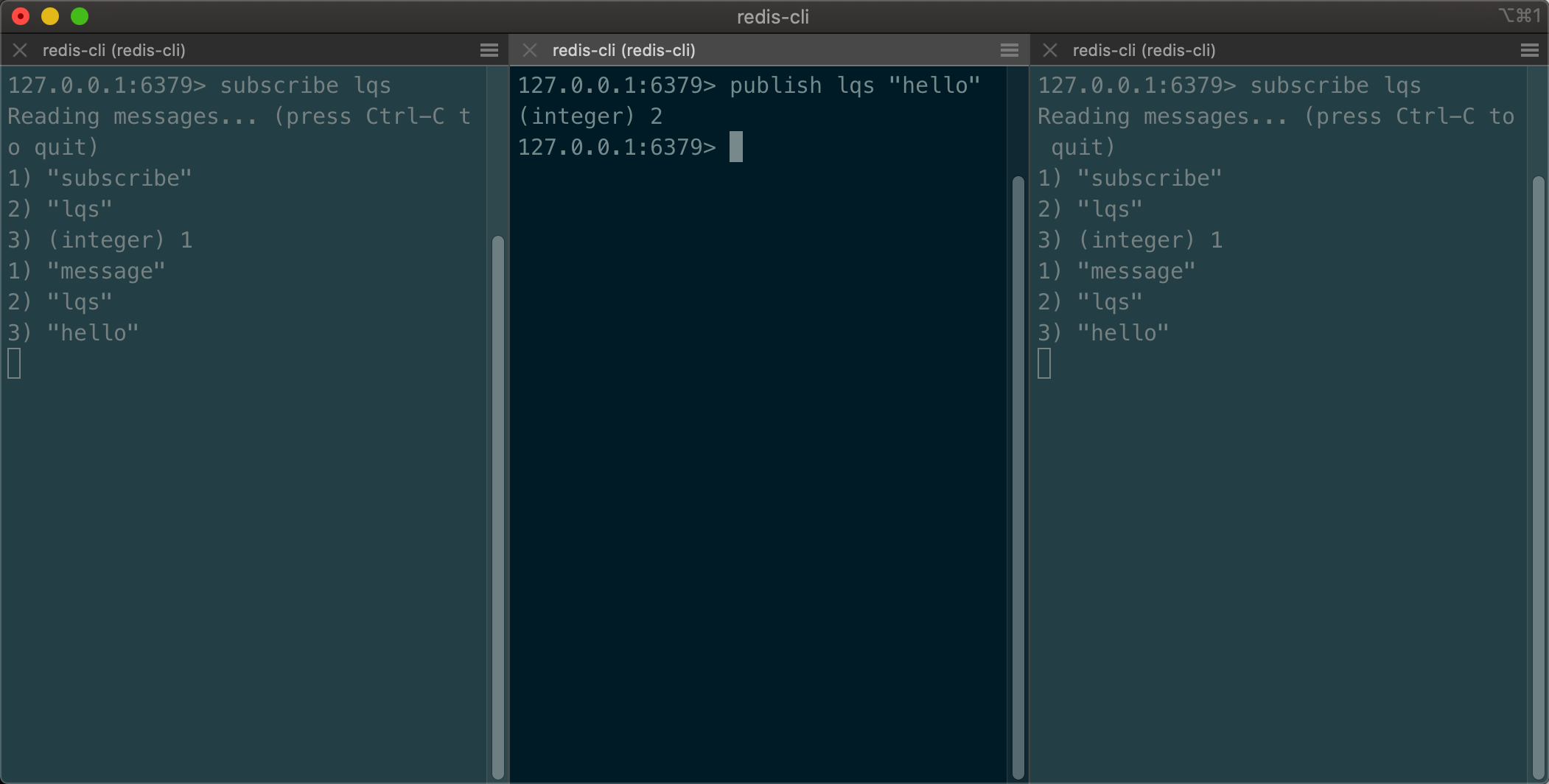
- 发布者发布再发布消息
- 订阅端会接收到消息
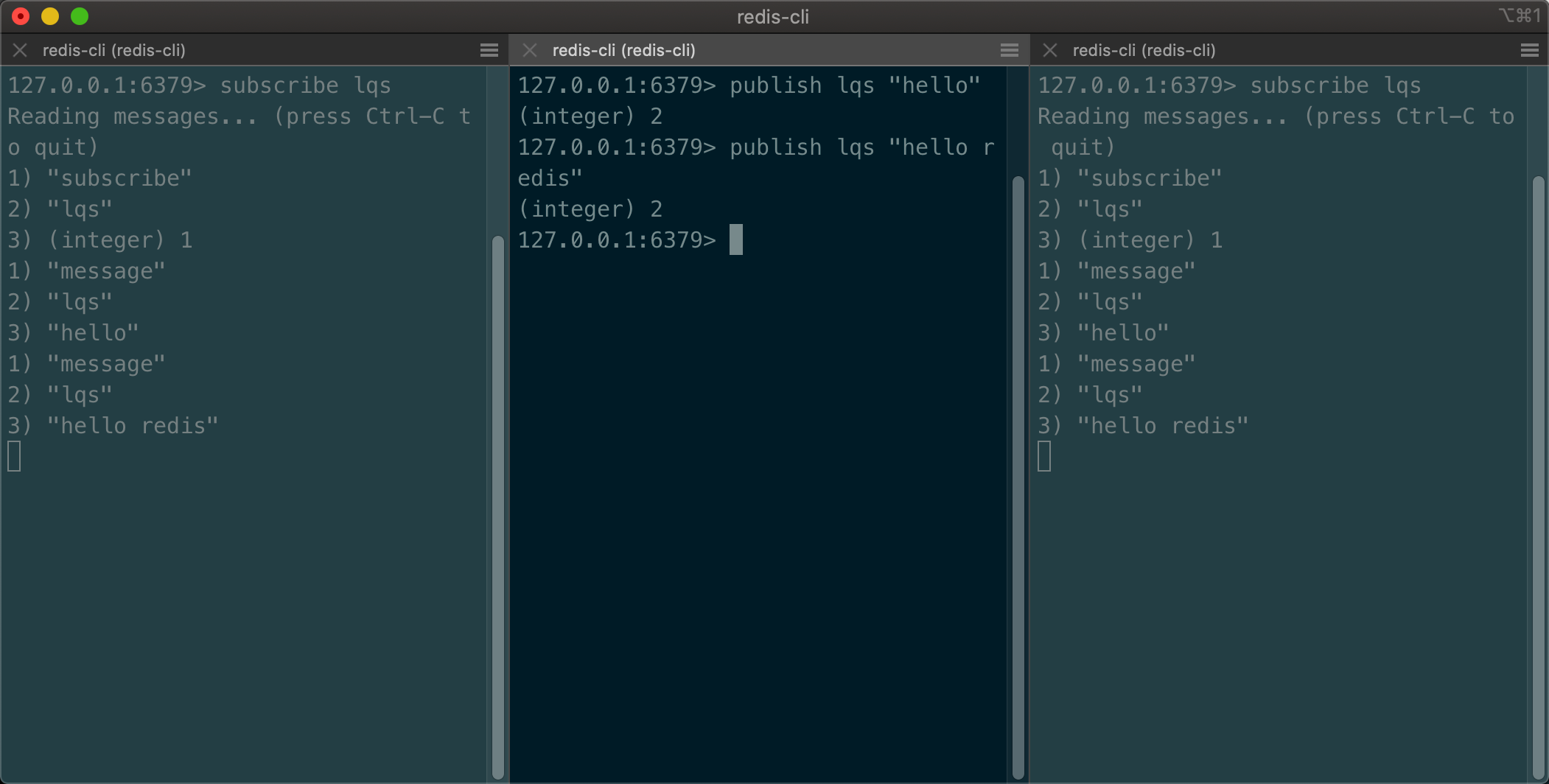
原理

使用场景
- 实时消息系统
- 群聊天室
更复杂的会使用 MQ
Redis 主从复制
- 将一台 Redis 服务器的数据复制到其他 redis 服务器。
- 前者为主节点(Master),后者为从节点(Slave)。
- 数据复制为单向的,只能从主节点到从节点。
- Master 以写为主,Slave 以读为主。
作用
- 数据冗余:实现数据热备份,是持久化之外的数据冗余方式
- 服务冗余:当主节点出问题时,可由从节点提供服务,实现快速故障恢复。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,从节点提供读服务,分担负载。在写少读多读情况下可大大提高 redis 服务器读并发量
- 高可用基石:哨兵和集群实施的基础
工程中,只用一台服务器是不行的,原因:
- 结构上,单个 redis 会发生单点故障,一台服务器需要处理所有的请求负载,压力太大
- 容量上,单台 Redis 的最大使用内存不应该超过 20g
- 很多数据,如电商网站的商品数据,一般都是写少读多,适合使用主从复制
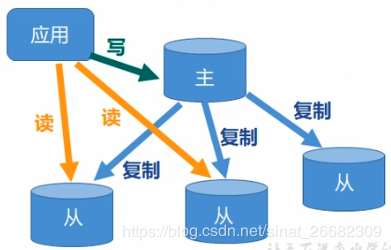
环境配置
1 | |
注意:使用 Docker 可以简单的部署集群,此处只用实现伪集群,了解即可
原理:将 redis.conf 复制为多份,启动时使用不同配置文件启动即可
- 复制多份配置文件
- 修改复制配置文件的几项关键内容
- 端口
- pid 名字
- log 文件名字
- dump.rdb 名字
- 以不同配置文件分别启动 redis-server
- 配置一主二从
1 | |
细节
- 确定主从之后,主机可以写,从机不可再进行写操作
- 主机断开连接之后,从机连接到主机的,但是没有写操作,这个时候如果重启了,就会变回主机。只要变回从机,立马就会从从机中获取值
主从复制原理
- 总结的不太好,不过发现一篇不错的博客,redis 主从复制原理,有时间了好好总结一下。
- Slave 启动成功连接到 Matser 后发送一个 sync 同步命令
- Master 接到命令,启动后台的存盘进程,同时手机所有接收到的用于修改数据集命令。在后台执行完毕之后,Master 将传送整个数据文件到 Slave,并完成一次完全同步
- 全量复制:
- 增量复制:
………………
哨兵模式
自动选举主机的模式
- 主服务器宕机之后,手动将其中一台服务器升级为主服务器,需要人工干预,费时费力,导致一段时间内的服务不可用,一般不推荐使用。现在一般使用哨兵模式。Redis 自 2.8 版本开始正式提供了 Sentinel 架构来解决此问题
优点:
- 哨兵集群,基于主从复制模式,所有主从配置的优点,它都有
- 主从可以切换,故障可以转移,系统可用性会更好
- 哨兵模式就是主从模式的升级,手动–>自动,健壮性更好
缺点:
- Redis 不方便在线扩容,集群容量一旦到达上限,在线扩容就比较麻烦
哨兵模式的全部配置
Redis 缓存穿透和雪崩(面试&常用)
- 关系到服务的高可用
缓存穿透
用户查询一个数据,Redis 中没有查询到,缓存未命中,于是向持久层数据库进行查询,也没有查询到结果,于是本次查询失败。当很多种这个情况发生时,会给持久层数据库带来很大压力,即缓存穿透
- 解决方案
布隆过滤器
一种数据结构,对所有可能的查询的参数以 hash 形式存储,在控制层先进性校验,不符合则丢弃,避免了对底层存储系统的查询压力
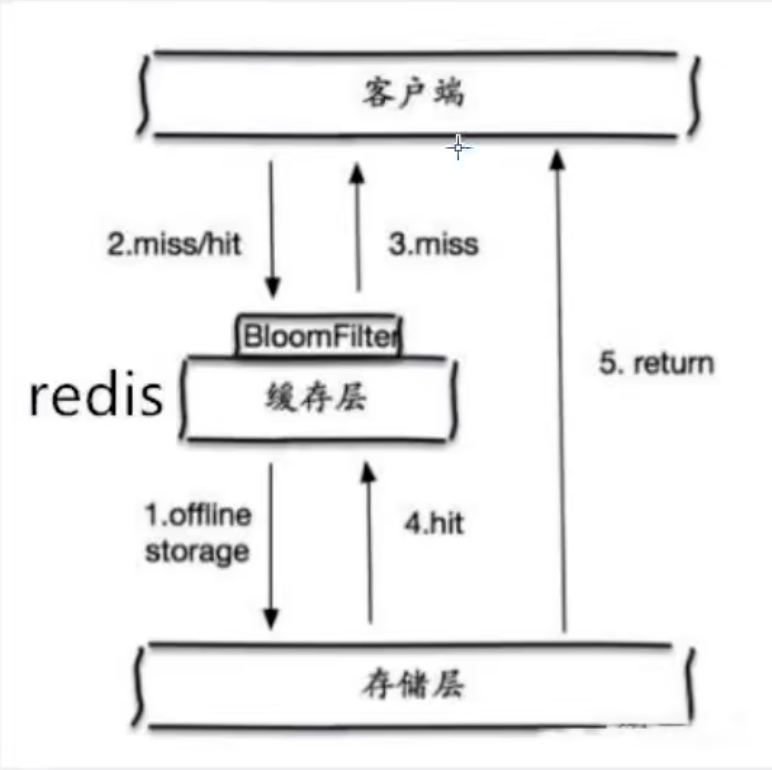
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时设置一个过期时间。之后再访问这个数据将会从缓存中获取,保护后端数据源
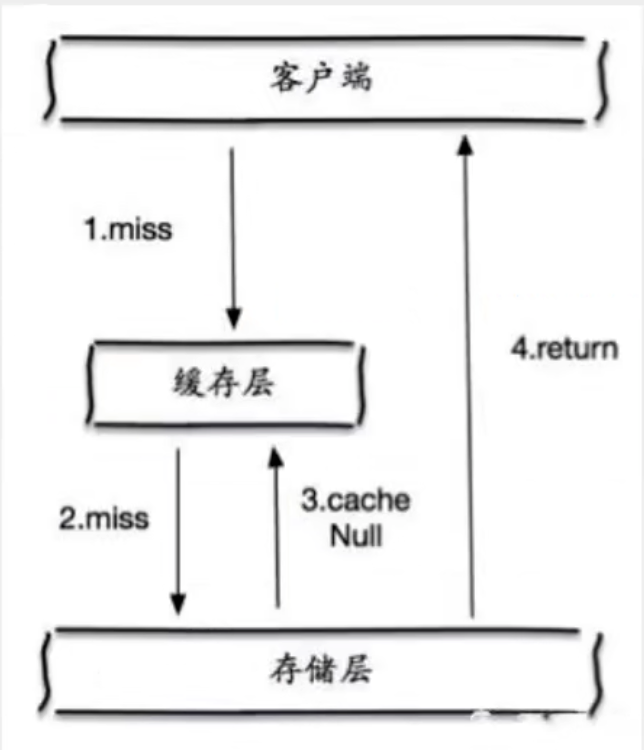
带来两个问题
- 如果空值被缓存起来,意味着缓存需要更多的空间存储更多的键,因为其中可能有很多空值的键
- 基石对空值设置了过期时间,还是会存在缓存层和存储层会有一段时间窗口的不一致,这对于需要一致性的业务需求有一定影响
缓存击穿
指一个 key 非常热点,不停扛着大并发,集中对一个点进行访问,当着个 key 失效多瞬间,持续多大并发就会击破缓存,直接请求数据库
- 解决方案
设置热点数据永不过期
- 从缓存层面看,没有设置过期时间,所以不会出现热点 key 过气候产生的问题
加互斥锁
- 分布式锁:使用分布式锁,保证每个 key 同时只有一个线程去查询后端服务,其他线程没有获得分布式锁多权限,只需要等待即可。这种方式将高并发多压力转移到了分布式锁,因此对分布式锁的考验很大
缓存雪崩
在某一个时间段,缓存集中过期失效,Redis 宕机
eg:双十二之前一个小时设置了时间为一小时的一批缓存,当双十二零点时,缓存集体失效,此时有大量访问,查询全部落到数据库。数据库产生周期性多压力波峰,所有请求同时到持久层,导致持久层挂掉。
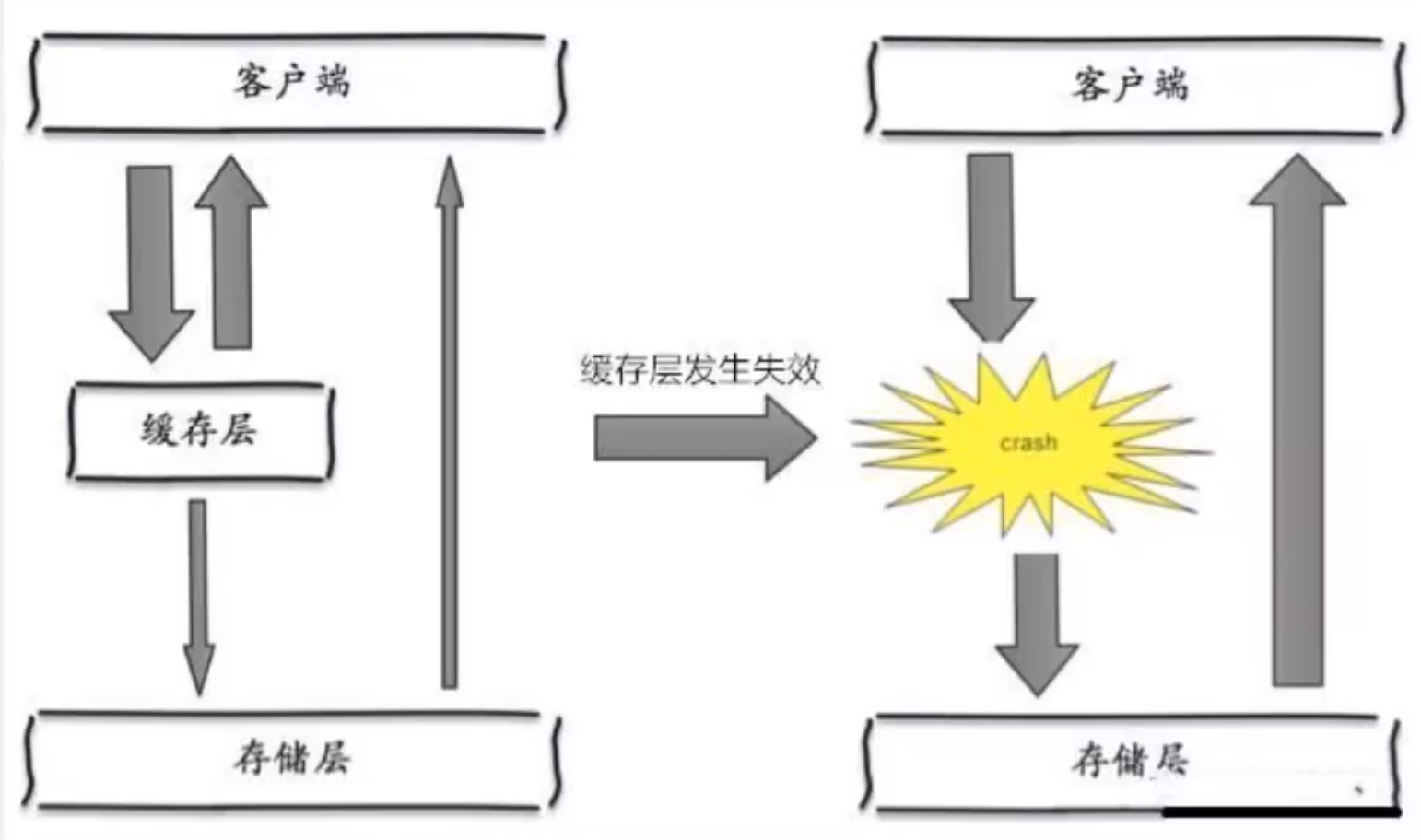
- 解决方案
Redis 高可用
增加几台 Redis 服务器,一台挂掉其他的还能继续工作。异地多活
限流降级
缓存失效后,通过加锁或队列来控制读数据库写缓存多线程数量。比如对某个 key 只允许一个线程查询数据和写缓存,其他线程等待
数据预热
正式部署前,把可能多数据预先访问一遍,这样部分可能大量访问多数据就会加载到缓存中。载即将发生大并发访问前手动触发加载缓存不同的 key,设置不同多过期时间,让缓存失效的时间尽量均匀
小结
资料获取:公众号回复 Redis 即可